https://www.kaggle.com/datasets/olistbr/brazilian-ecommerce?select=olist_products_dataset.csv
Brazilian E-Commerce Public Dataset by Olist
100,000 Orders with product, customer and reviews info
www.kaggle.com
PROC SQL OUTOBS=10;
CREATE TABLE Brazilian AS
SELECT DISTINCT A.REVIEW_SCORE
FROM WORK.OLIST_ORDER_REVIEWS_DATASET AS A
ORDER BY 1
;QUIT;
PROC SQL;
CREATE TABLE Brazilian_2 AS
SELECT ORDER_PURCHASE_TIMESTAMP AS YM
, COUNT(DISTINCT ORDER_ID) AS ORDER_COUNT
FROM WORK.OLIST_ORDERS_DATASET
GROUP BY 1
ORDER BY 1;
QUIT;
/* DISTINCT 시 데이터값 다름 (N)*/
PROC SQL;
CREATE TABLE Brazilian_3 AS
SELECT COUNT(*) AS CNT
, COUNT(ORDER_ID) AS ORDER_COUNT_NOT_DISTINCT
, COUNT(DISTINCT ORDER_ID) AS ORDER_COUNT
FROM WORK.OLIST_ORDER_ITEMS_DATASET
;QUIT;
/* 모두 동일(1) */
PROC SQL;
CREATE TABLE Brazilian_3 AS
SELECT COUNT(*) AS CNT
, COUNT(ORDER_ID) AS ORDER_COUNT_NOT_DISTINCT
, COUNT(DISTINCT ORDER_ID) AS ORDER_COUNT
FROM WORK.OLIST_ORDERS_DATASET
;QUIT;
PROC SQL;
CREATE TABLE Brazilian_3 AS
SELECT ORDER_ID
FROM WORK.OLIST_ORDER_ITEMS_DATASET
WHERE ORDER_ID = '00010242fe8c5a6d1ba2dd792cb16214'
;QUIT;
/* 3. 카테고리별 주문정보 확인 */
PROC SQL;
CREATE TABLE WORK.TMP1 AS
SELECT COUNT(DISTINCT A.ORDER_ID) AS CNT
, SUM(A.PRICE) AS PRICE
, MEAN(A.FREIGHT_VALUE) AS TOTAL_VALUE
FROM WORK.OLIST_ORDER_ITEMS_DATASET AS A
LEFT JOIN WORK.OLIST_ORDERS_DATASET AS B
ON A.ORDER_ID = B.ORDER_ID
LEFT JOIN WORK.OLIST_PRODUCTS_DATASET AS C
ON A.PRODUCT_ID = C.PRODUCT_ID
LEFT JOIN WORK.PRODUCT_CATEGORY_NAME_TRANSLATIO AS D
ON C.PRODUCT_CATEGORY_NAME = D.PRODUCT_CATEGORY_NAME
;QUIT;

1. 월별 주문 건수 확인 (count)
/* 어떤 카테고리가 가장 많이 팔렸나? */
/* 카테고리별 주문정보 확인 */
/* 1단계: DATETIME 값에서 날짜만 추출 후 YYYY-MM 생성 */
data orders_monthly;
set WORK.OLIST_ORDERS_DATASET;
/* DATETIME → DATE 변환 */
purchase_date = datepart(order_purchase_timestamp);
format purchase_date date9.; /* 예: 02OCT2017 */
/* DATE → YYYYMM 문자 생성 */
YM = put(intnx('month', purchase_date, 0), yymmn6.);
format YM $7.;
run;
/* 2단계: 월별 고유 주문 수 집계 */
proc sql;
create table monthly_order_count as
select
YM,
count(distinct order_id) as order_count
from
orders_monthly
group by
YM
order by
YM;
quit;
/* 하나의 쿼리 안에 넣기 */
proc sql;
create table monthly_order_count as
select
put(intnx('month', datepart(order_purchase_timestamp), 0), yymmn6.) as YM format=$7.,
count(distinct order_id) as order_count
from
WORK.OLIST_ORDERS_DATASET
group by
calculated YM
order by
calculated YM;
quit;
2. DISTINCT 활용해서 테이블간 1:N 관계 파악
/* 모두 동일(1) */
PROC SQL;
CREATE TABLE Brazilian_3 AS
SELECT COUNT(*) AS CNT
, COUNT(ORDER_ID) AS ORDER_COUNT_NOT_DISTINCT
, COUNT(DISTINCT ORDER_ID) AS ORDER_COUNT
FROM WORK.OLIST_ORDERS_DATASET
;QUIT;
3. 카테고리별 주문정보 확인
Q (어떤 카테고리가 가장 많이 팔렸나?)
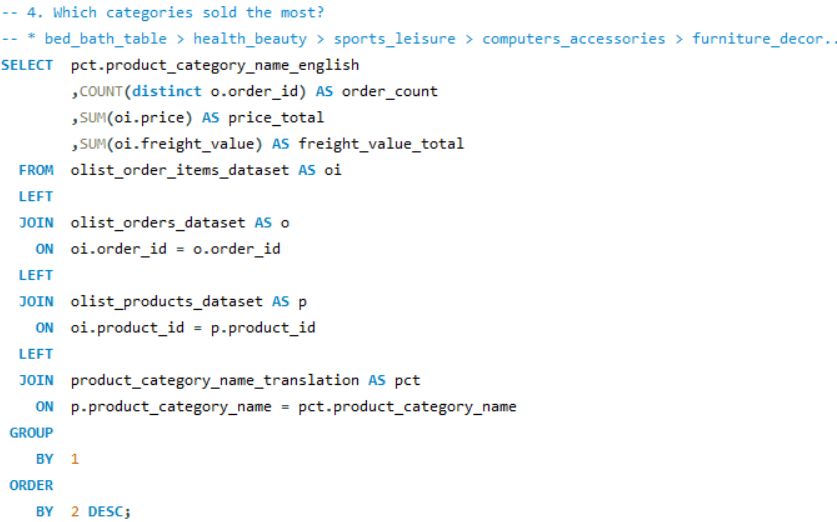
PROC SQL;
CREATE TABLE WORK.TMP1 AS
SELECT DISTINCT D.PRODUCT_CATEGORY_NAME_ENGLISH
, COUNT(DISTINCT A.ORDER_ID) AS CNT
, SUM(A.PRICE) AS PRICE
, MEAN(A.FREIGHT_VALUE) AS TOTAL_VALUE
FROM WORK.OLIST_ORDER_ITEMS_DATASET AS A
LEFT JOIN WORK.OLIST_ORDERS_DATASET AS B
ON A.ORDER_ID = B.ORDER_ID
LEFT JOIN WORK.OLIST_PRODUCTS_DATASET AS C
ON A.PRODUCT_ID = C.PRODUCT_ID
LEFT JOIN WORK.PRODUCT_CATEGORY_NAME_TRANSLATIO AS D
ON C.PRODUCT_CATEGORY_NAME = D.PRODUCT_CATEGORY_NAME
WHERE 1=1
AND D.PRODUCT_CATEGORY_NAME_ENGLISH IS NOT NULL
GROUP BY 1
ORDER BY 2
;QUIT;
4. olist_order_items_dataset 테이블 컬럼인 가격(price)과 화물가치(freight_value)의 합이 총 주문금액인가?

PROC SQL;
CREATE TABLE WORK.TMP2 AS
SELECT A.ORDER_ID
, SUM(A.PRICE) AS SUM
, SUM(A.FREIGHT_VALUE) AS SUM_VALUE
, SUM(A.PRICE) + SUM(A.FREIGHT_VALUE) AS TOTAL_ORDER
FROM WORK.OLIST_ORDER_ITEMS_DATASET AS A
WHERE 1=1
GROUP BY 1
;QUIT;
5. 가장 많이 주문한 도시는 어디인가?
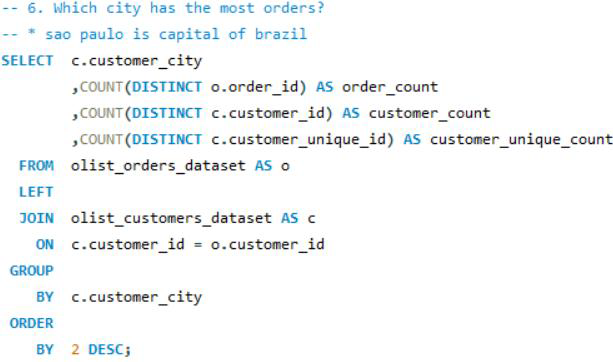
/* 5. 가장 많이 주문한 도시는 어디인가? */
PROC SQL;
CREATE TABLE WORK.TMP3 AS
SELECT B.CUSTOMER_CITY
, COUNT(DISTINCT A.ORDER_ID) AS ORDER_COUNT
, COUNT(DISTINCT B.CUSTOMER_ID) AS CUSTOMER_CNT
, COUNT(DISTINCT B.CUSTOMER_UNIQUE_ID) AS CUSTOMER_UNIQUE_CNT
FROM WORK.OLIST_ORDERS_DATASET AS A
LEFT JOIN WORK.OLIST_CUSTOMERS_DATASET AS B
ON A.CUSTOMER_ID = B.CUSTOMER_ID
GROUP BY B.CUSTOMER_CITY
ORDER BY 2 DESC
;QUIT;
6. 누가 가장 많이 샀는가?

/* 주문 수 구간별 고객 수 집계 */
proc sql;
create table customer_segment_summary as
select
case
when order_count >= 5 then '5_Order_Over'
when order_count = 4 then '4_Order'
when order_count = 3 then '3_Order'
when order_count = 2 then '2_Order'
when order_count = 1 then '1_Order'
end as order_segment,
count(distinct customer_unique_id) as customer_cnt
from
WORK.OLIST_CUSTOMERS_DATASET
group by
case
when order_count >= 5 then '5_Order_Over'
when order_count = 4 then '4_Order'
when order_count = 3 then '3_Order'
when order_count = 2 then '2_Order'
when order_count = 1 then '1_Order'
end
order by
order_segment;
quit;
7. 함께 자주 구매하는 제품은 무엇인가?

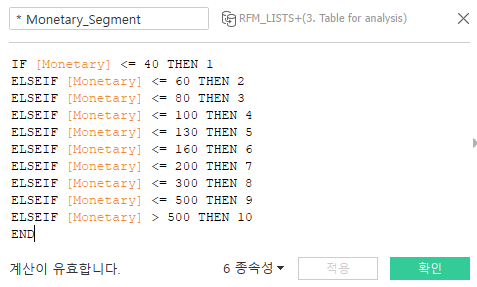
* RFM(Recency, Frequency, Monetary) 분석 테이블 : 고객 세분화(segmentation)
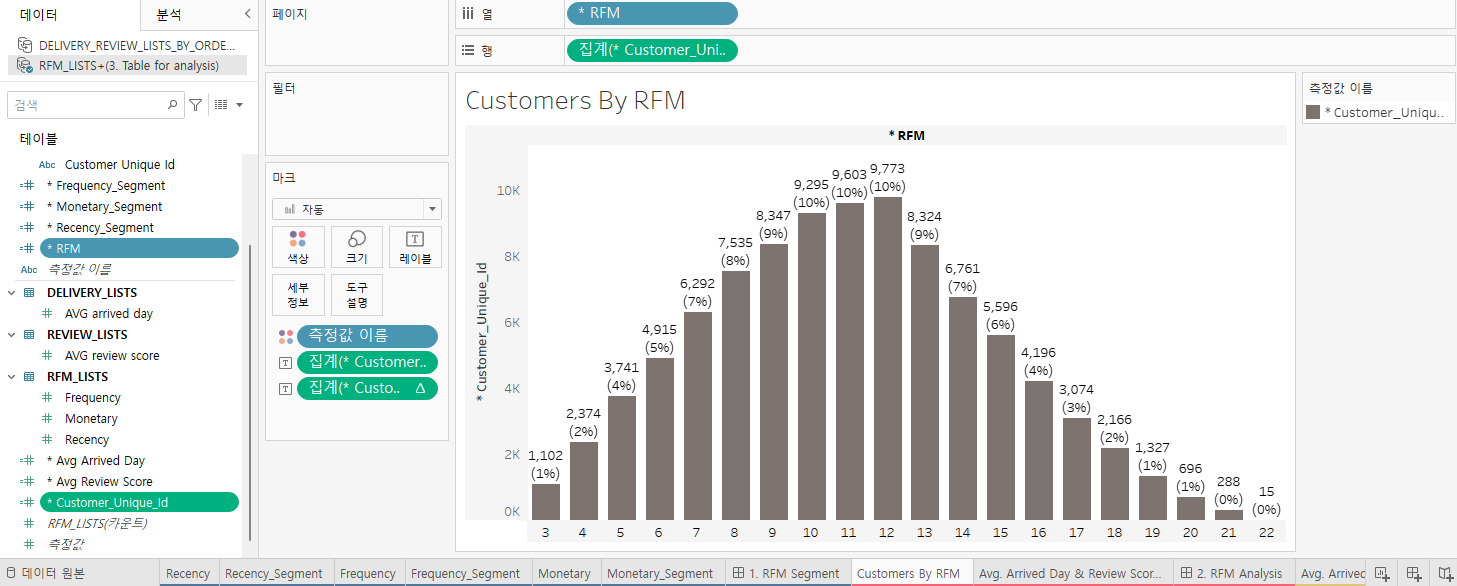

- Recency: 최근에 구매했는가?
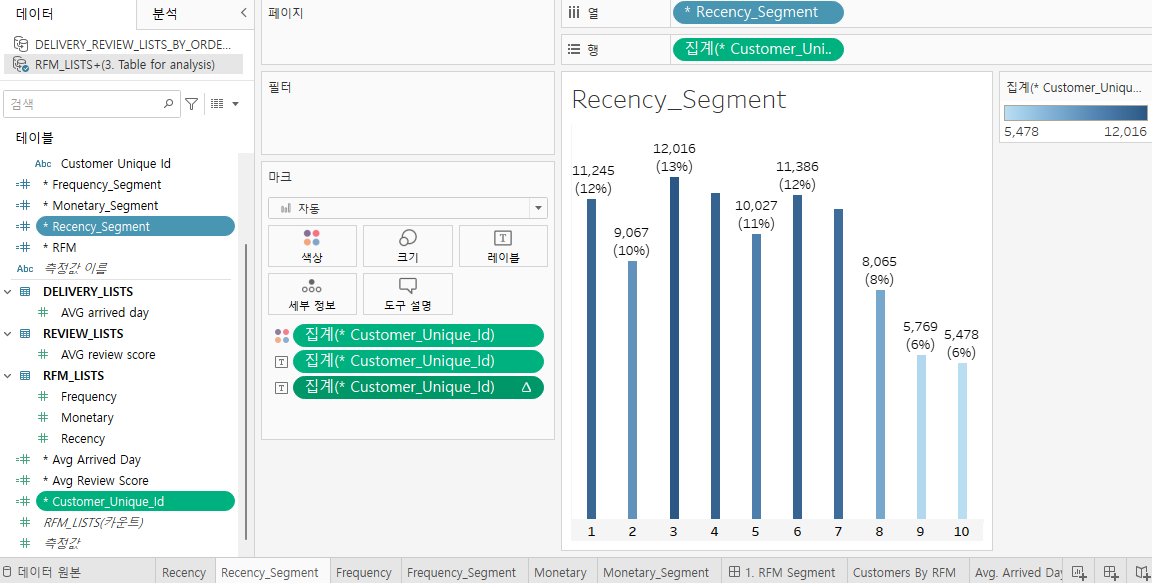

- Frequency: 자주 구매했는가?
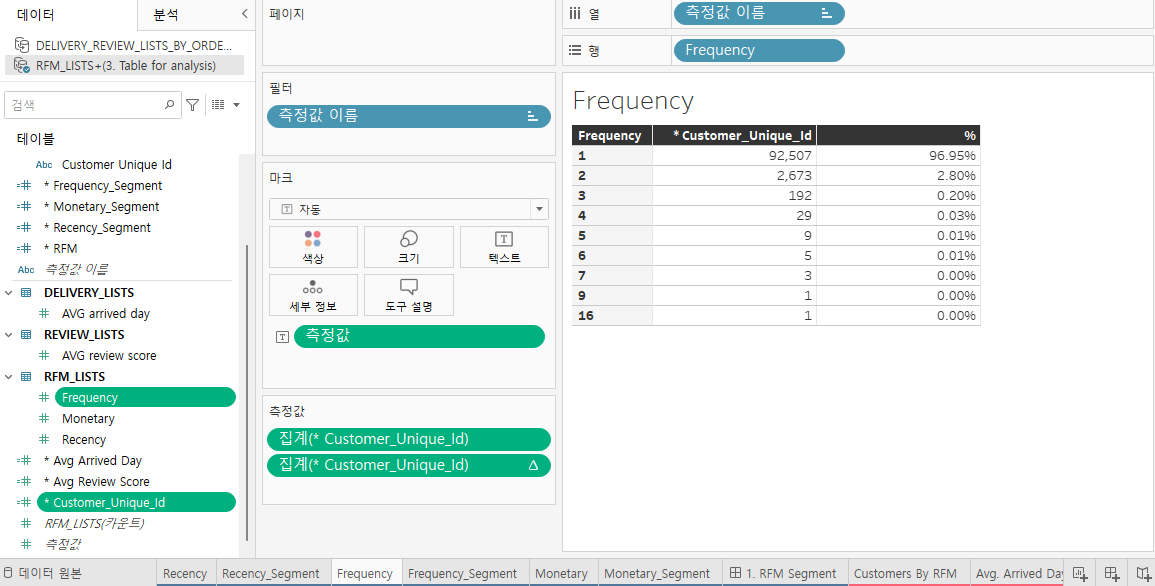
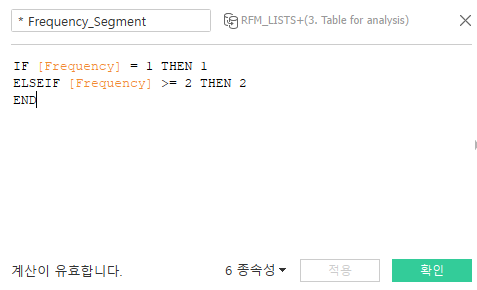
- Monetary: 구매 금액은 얼마인가?

'개인 프로젝트 > 데이터 분석 프로젝트' 카테고리의 다른 글
| 한국투자증권 API 활용 주식종목 시세 예측 (0) | 2026.04.12 |
|---|---|
| [Kaggle] Credit Card Fraud Detection(분류 실습) (0) | 2025.07.23 |
| [Kaggle] Brazilian E-Commerce Public Dataset by Olist (3) | 2025.07.18 |
| [Kaggle] House Prices - Advanced Regression Techniques (0) | 2025.07.16 |
| [Kaggle] Bank_Loan_modelling / 은행 대출 모델링 (0) | 2025.07.15 |



댓글