(과거)
RNN, LSTM, GRU 등
기존의 자연어 처리 모들 : 순환 신경망 기반 (Recursive)
LSTM, GRU 같은 접근이 있었지만 한계가 존재함.
순차처리 -> 병렬처리 어려움.
Word2Vec : 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다.
biLMs - biELMo - biLSTM : Language Model (ElMo representation + Embedding vector) : 정방향, 역방향 분리, 약하게 연결
Bert = Encoder only transformers : 전체적인 양방향성을 갖기 위해서
- WordPiece embeddings > 3만개의 토큰 vocabulary 사용
- 스페셜 토큰 사용 : [CLS][EOS][MASK][PAD] 등
Bert 중요 개념 : Self Attention
- Query, Key : 두 벡터 사이의 유사성
- Scale : QK 내적 결과로 커져버린 벡터 값을 스케일링
- Softmax : 계산된 attention score를 합이 1이 되게 변화
- Value : attention을 각 토큰에 부여하기 위해 내적
* Sparse Attention : attention의 희소한 부분 집합만을 계산하는 접근
* Group Query Attention : Multi head에서 query head를 그룹으로 분할
- Bidirectional : Bert - 양방향성 모델
- Pretraining : 양방향성 이해를 높이기 위해 도입 (Masked Language Model, Mask 처리된 단어를 복원하는 Task)
Fine - tuning
Ablation Studies



- Encoder-only : BERT, 압축만 하는 상태
- Decoder-only : GPT*
- Transformer : Input과 Output 크기가 동일.

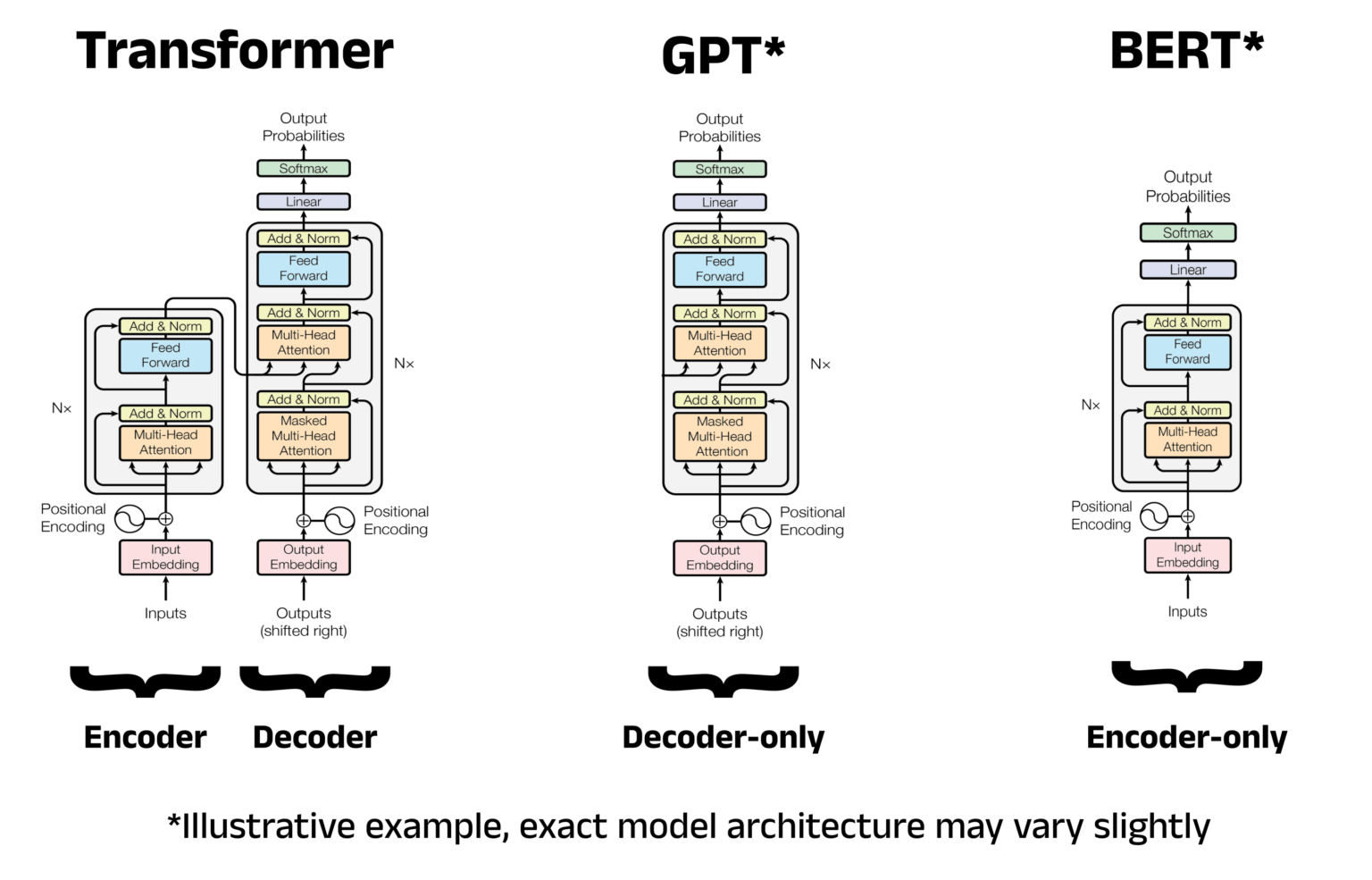
BERT : 생성형 GPT에 사용되지 않는 이유는 전체 토큰이 다 맞아야 되기 때문에, 생성형에 적합하진 않은 모델임.
GPT : 다음 토큰에 대한 범위를 맞출 수 있어서, 생성형에 적합.
Next Sentence Prediction : 문장과 문장 사이의 관계를 도입하기 위해 사용
'개인 프로젝트 > [LLM] 논문리뷰' 카테고리의 다른 글
| [논문리뷰] RoBERT 언어모델 발표자료 (0) | 2025.04.06 |
|---|---|
| [논문리뷰] 기계 번역 모델의 발전방향 및 비교 (1) | 2025.04.06 |
| [논문리뷰] BERT-RoBERTa (0) | 2025.04.01 |
| [논문] RNN_2014_Sequence to Sequence Learning with Neural Networks (0) | 2025.03.24 |
| [논문] Attention - Neural Machine Translation by Jointly Learning to Align and Translate (2014) (0) | 2025.03.19 |




댓글