[문제 1. Bag-of-features 구현 및 Classifier 학습 (30 pts)]
1-1. [특징 추출]
코드 상에서 주어진 Keypoint를 통하여, 각각의 이미지마다 특징을 추출하세요.
이 때, OpenCV 패키지를 활용하여, SIFT와 같은 특징을 추출하세요. (자세한 사항은 템플릿 코드를 참고)
1-2. [Bag-of-Features 구현]
K-means을 통해 구해진 codebook을 통하여, 각각의 이미지의 특징을
인코딩(histogram화 혹은 양자화 라고도 합니다.) 하세요.
(자세한 사항은 템플릿 코드를 참고)
1-3. [SVM 을 통한 이미지 분류]
Bag-of-Features 알고리즘을 통해 얻어진 인코딩된 벡터를 통해, SVM을 학습하세요.
템플릿 코드 기준으로는, sklearn 패키지의 LinearSVC를 활용하여 SVM 학습을 구현하시면 됩니다.
이후 Confusion matrix를 파라미터를 변경해가며 분석해보세요.
(https://scikit-learn.org/stable/modules/generated/sklearn.metrics.confusion_matrix.html 참고)
# 최종 1번 코드
import time
import cv2
import glob
import os
import numpy as np
import random
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.kernel_approximation import AdditiveChi2Sampler
from sklearn.svm import LinearSVC
BASE_PATH = "/content"
start_time = time.time()
'''
Parameters
'''
patch_stride = 16
K = 20
'''
Load Dataset
(don't modify)
'''
def scene15():
train_folders = glob.glob(os.path.join(BASE_PATH, "train", "*"))
train_folders.sort()
classes = dict()
x_train = list()
y_train = list()
for index, folder in enumerate(train_folders):
label = os.path.basename(folder)
classes[label] = index
paths = glob.glob(os.path.join(folder, "*"))
for path in paths:
x_train.append(cv2.imread(path, 0))
y_train.append(index)
x_test = list()
y_test = list()
test_folders = glob.glob(os.path.join(BASE_PATH, "test", "*"))
test_folders.sort()
for folder in test_folders:
label = os.path.basename(folder)
index = classes[label]
paths = glob.glob(os.path.join(folder, "*"))
for path in paths:
x_test.append(cv2.imread(path, 0))
y_test.append(index)
return x_train, y_train, x_test, y_test, sorted(classes.keys())
print("Load Dataset ...")
x_train, y_train, x_test, y_test, labels_names = scene15()
combined = list(zip(x_train, y_train))
random.shuffle(combined)
x_train[:], y_train[:] = zip(*combined)
'''
Extract Patches
(don't modify)
'''
train_key_points = list()
train_feature_shapes = list()
for image in x_train:
h, w = image.shape
image_key_points = list()
for x in range(0, w, patch_stride):
for y in range(0, h, patch_stride):
image_key_points.append(cv2.KeyPoint(x, y, patch_stride))
train_key_points.append(image_key_points)
train_feature_shapes.append((len(range(0, w, patch_stride)), (len(range(0, h, patch_stride)))))
test_key_points = list()
test_feature_shapes = list()
for image in x_test:
h, w = image.shape
image_key_points = list()
for x in range(0, w, patch_stride):
for y in range(0, h, patch_stride):
image_key_points.append(cv2.KeyPoint(x, y, patch_stride))
test_key_points.append(image_key_points)
test_feature_shapes.append((len(range(0, w, patch_stride)), (len(range(0, h, patch_stride)))))
'''
P-1.1
'''
###################################################################################
# 아래의 코드의 빈 곳(None 부분)을 채우세요.
# None 부분 외의 부분은 가급적 수정 하지 말고, 주어진 형식에 맞추어
# None 부분 만을 채워주세요. 임의적으로 전체적인 구조를 수정하셔도 좋지만,
# 파이썬 코딩에 익숙 하지 않으시면, 가급적 틀을 유지하시는 것을 권장합니다.
# 1) descriptor를 선정하세요. (SIFT, SURF 등) OpenCV의 패키지를 사용하시면 됩니다.
# 2) for 반복문 안에서, 1)에서 정의한 descriptor를 통하여 features를 추출하세요.
# features의 차원은 (# of keypoints, feature_dim) 입니다.
###################################################################################
######## Write Your Code Here ##########
descriptor = cv2.SIFT_create() # Define your descriptor (e.g. SIFT)
########################################
train_features = list()
index = 0
for image, key_points in zip(x_train, train_key_points):
######## Write Your Code Here ##########
keypoints_used, features = descriptor.compute(image, key_points)
########################################
train_features.append(features)
index += 1
test_features = list()
index = 0
for image, key_points in zip(x_test, test_key_points):
# Write Your Code Here #################
keypoints_used, features = descriptor.compute(image, key_points)
########################################
test_features.append(features)
index += 1
print("Extract Test Features ... {:4d}/{:4d}".format(index, len(x_test)))
'''
Normalizing
(don't modify)
'''
flattened_train_features = np.concatenate(train_features, axis=0)
pca = PCA(n_components=flattened_train_features.shape[-1], whiten=True)
pca.fit(flattened_train_features)
train_normalized_features = list()
index = 0
for features in train_features:
features = pca.transform(features)
train_normalized_features.append(features)
index += 1
print("Normalize Train Features ... {:4d}/{:4d}".format(index, len(train_features)))
test_normalized_features = list()
index = 0
for features in test_features:
features = pca.transform(features)
test_normalized_features.append(features)
index += 1
print("Normalize Test Features ... {:4d}/{:4d}".format(index, len(test_features)))
'''
P-1.2 :Make Codebook
'''
###################################################################################
# 아래의 코드의 빈 곳(None 부분)을 채우세요.
# None 부분 외의 부분은 가급적 수정 하지 말고, 주어진 형식에 맞추어 None 부분 만을 채워주세요
# 1) 함수 encode 부분 안의 None 부분을 채우세요.
# distances는 K means 알고리즘을 통해 얻어진 centroids, 즉 codewords(visual words)와 각 이미지의 특징들 간의 거리 입니다.
# distances 값을 이용하여, features(# of keypoints, feature_dim)를 인코딩(histogram 혹은 quantization이라고도 함) 하세요.
# 인코딩된 결과인 representations은 K(centorid의 개수)로 표현되어야 합니다.
###################################################################################
class Codebook:
def __init__(self, K):
self.K = K
self.kmeans = KMeans(n_clusters=K, verbose=True)
def make_code_words(self, features):
self.kmeans.fit(features)
def encode(self, features, shapes):
distances = self.kmeans.transform(features)
# Write Your Code Here ###################################################
# 각 feature가 가장 가까운(거리 최소) centroid 인덱스
nearest = np.argmin(distances, axis=1) # shape: (num_features,)
# K차원 히스토그램(BoF 벡터)
representations = np.bincount(nearest, minlength=self.K).astype(np.int64)
##########################################################################
if np.array(representations).shape != (self.K, ):
print(np.array(representations).shape)
print("Your code may be wrong")
return representations
'''
Encode Codebook and encoded features
(Don't modify)
'''
### CODE BOOK Make ####
print("Make Codebook ...")
flattened_normalized_train_features = pca.transform(flattened_train_features)
codebook = Codebook(K)
codebook.make_code_words(flattened_normalized_train_features)
train_encoded_features = list()
index = 0
for features, shapes in zip(train_normalized_features, train_feature_shapes):
encoded_features = codebook.encode(features, shapes)
train_encoded_features.append(encoded_features)
index += 1
print("Encoding Train Features ... {:4d}/{:4d}".format(index, len(train_normalized_features)))
test_encoded_features = list()
index = 0
for features, shapes in zip(test_normalized_features, test_feature_shapes):
encoded_features = codebook.encode(features, shapes)
test_encoded_features.append(encoded_features)
index += 1
print("Encoding Text Features ... {:4d}/{:4d}".format(index, len(test_normalized_features)))
'''
Approximate Kernel for encoded features
(Don't modify)
'''
chi2sampler = AdditiveChi2Sampler(sample_steps=2)
chi2sampler.fit(train_encoded_features, y_train)
train_encoded_features = chi2sampler.transform(train_encoded_features)
test_encoded_features = chi2sampler.transform(test_encoded_features)
'''
P-1.3 : Classify Images with SVM
'''
###################################################################################
# 아래의 코드의 빈 곳을 채우세요.
# 1) 아래의 model 부분에 sklearn 패키지를 활용하여, Linear SVM(SVC) 모델을 정의하세요.
# 처음에는 SVM의 parameter를 기본으로 설정하여 구동하시길 권장합니다.
# 구동 성공 시, SVM의 C 값과 max_iter 파라미터 등을 조정하여 성능 향상을 해보시길 바랍니다.
###################################################################################
#parameter 값을 수정해가면서 성능향상을 해보시길 바랍니다.
model = LinearSVC(C=1.0, max_iter=5000, verbose=True)
print("Classify Images ...")
# Write Your Code Here ############################################################
X_train_bof = np.asarray(train_encoded_features)
X_test_bof = np.asarray(test_encoded_features)
model.fit(X_train_bof, y_train)
train_score = model.score(X_train_bof, y_train)
test_score = model.score(X_test_bof, y_test)
###################################################################################
elapsed_time = time.time() - start_time
'''
Print Results
'''
print()
print("=" * 90)
print("Train Score: {:.5f}".format(train_score))
print("Test Score: {:.5f}".format(test_score))
print("Elapsed Time: {:.2f} secs".format(elapsed_time))
print("=" * 90)
'''For confusion matrix'''
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
# Write Your Code Here ############################################################
y_pred = model.predict(X_test_bof)
Confusion_Matrix = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=Confusion_Matrix, display_labels=labels_names)
fig, ax = plt.subplots(figsize=(8, 8))
disp.plot(ax=ax, xticks_rotation=45, colorbar=False)
plt.title("Confusion Matrix (LinearSVC + BoF)")
plt.tight_layout()
plt.show()
###################################################################################

# 최종 1-2 인코딩 그래프 추가 완료
import time
import cv2
import glob
import os
import numpy as np
import random
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
from sklearn.kernel_approximation import AdditiveChi2Sampler
from sklearn.svm import LinearSVC
BASE_PATH = "/content"
start_time = time.time()
'''
Parameters
'''
patch_stride = 16
K = 20
'''
Load Dataset
(don't modify)
'''
def scene15():
train_folders = glob.glob(os.path.join(BASE_PATH, "train", "*"))
train_folders.sort()
classes = dict()
x_train = list()
y_train = list()
for index, folder in enumerate(train_folders):
label = os.path.basename(folder)
classes[label] = index
paths = glob.glob(os.path.join(folder, "*"))
for path in paths:
x_train.append(cv2.imread(path, 0))
y_train.append(index)
x_test = list()
y_test = list()
test_folders = glob.glob(os.path.join(BASE_PATH, "test", "*"))
test_folders.sort()
for folder in test_folders:
label = os.path.basename(folder)
index = classes[label]
paths = glob.glob(os.path.join(folder, "*"))
for path in paths:
x_test.append(cv2.imread(path, 0))
y_test.append(index)
return x_train, y_train, x_test, y_test, sorted(classes.keys())
print("Load Dataset ...")
x_train, y_train, x_test, y_test, labels_names = scene15()
combined = list(zip(x_train, y_train))
random.shuffle(combined)
x_train[:], y_train[:] = zip(*combined)
'''
Extract Patches
(don't modify)
'''
train_key_points = list()
train_feature_shapes = list()
for image in x_train:
h, w = image.shape
image_key_points = list()
for x in range(0, w, patch_stride):
for y in range(0, h, patch_stride):
image_key_points.append(cv2.KeyPoint(x, y, patch_stride))
train_key_points.append(image_key_points)
train_feature_shapes.append((len(range(0, w, patch_stride)), (len(range(0, h, patch_stride)))))
test_key_points = list()
test_feature_shapes = list()
for image in x_test:
h, w = image.shape
image_key_points = list()
for x in range(0, w, patch_stride):
for y in range(0, h, patch_stride):
image_key_points.append(cv2.KeyPoint(x, y, patch_stride))
test_key_points.append(image_key_points)
test_feature_shapes.append((len(range(0, w, patch_stride)), (len(range(0, h, patch_stride)))))
'''
P-1.1
'''
###################################################################################
# 아래의 코드의 빈 곳(None 부분)을 채우세요.
# None 부분 외의 부분은 가급적 수정 하지 말고, 주어진 형식에 맞추어
# None 부분 만을 채워주세요. 임의적으로 전체적인 구조를 수정하셔도 좋지만,
# 파이썬 코딩에 익숙 하지 않으시면, 가급적 틀을 유지하시는 것을 권장합니다.
# 1) descriptor를 선정하세요. (SIFT, SURF 등) OpenCV의 패키지를 사용하시면 됩니다.
# 2) for 반복문 안에서, 1)에서 정의한 descriptor를 통하여 features를 추출하세요.
# features의 차원은 (# of keypoints, feature_dim) 입니다.
###################################################################################
######## Write Your Code Here ##########
descriptor = cv2.SIFT_create() # Define your descriptor (e.g. SIFT)
########################################
train_features = list()
index = 0
for image, key_points in zip(x_train, train_key_points):
######## Write Your Code Here ##########
keypoints_used, features = descriptor.compute(image, key_points)
########################################
train_features.append(features)
index += 1
test_features = list()
index = 0
for image, key_points in zip(x_test, test_key_points):
# Write Your Code Here #################
keypoints_used, features = descriptor.compute(image, key_points)
########################################
test_features.append(features)
index += 1
print("Extract Test Features ... {:4d}/{:4d}".format(index, len(x_test)))
'''
Normalizing
(don't modify)
'''
flattened_train_features = np.concatenate(train_features, axis=0)
pca = PCA(n_components=flattened_train_features.shape[-1], whiten=True)
pca.fit(flattened_train_features)
train_normalized_features = list()
index = 0
for features in train_features:
features = pca.transform(features)
train_normalized_features.append(features)
index += 1
print("Normalize Train Features ... {:4d}/{:4d}".format(index, len(train_features)))
test_normalized_features = list()
index = 0
for features in test_features:
features = pca.transform(features)
test_normalized_features.append(features)
index += 1
print("Normalize Test Features ... {:4d}/{:4d}".format(index, len(test_features)))
'''
P-1.2 :Make Codebook
'''
###################################################################################
# 아래의 코드의 빈 곳(None 부분)을 채우세요.
# None 부분 외의 부분은 가급적 수정 하지 말고, 주어진 형식에 맞추어 None 부분 만을 채워주세요
# 1) 함수 encode 부분 안의 None 부분을 채우세요.
# distances는 K means 알고리즘을 통해 얻어진 centroids, 즉 codewords(visual words)와 각 이미지의 특징들 간의 거리 입니다.
# distances 값을 이용하여, features(# of keypoints, feature_dim)를 인코딩(histogram 혹은 quantization이라고도 함) 하세요.
# 인코딩된 결과인 representations은 K(centorid의 개수)로 표현되어야 합니다.
###################################################################################
class Codebook:
def __init__(self, K):
self.K = K
self.kmeans = KMeans(n_clusters=K, verbose=True)
def make_code_words(self, features):
self.kmeans.fit(features)
def encode(self, features, shapes):
distances = self.kmeans.transform(features)
# Write Your Code Here ###################################################
# 각 feature가 가장 가까운(거리 최소) centroid 인덱스
nearest = np.argmin(distances, axis=1) # shape: (num_features,)
# K차원 히스토그램(BoF 벡터)
representations = np.bincount(nearest, minlength=self.K).astype(np.int64)
##########################################################################
if np.array(representations).shape != (self.K, ):
print(np.array(representations).shape)
print("Your code may be wrong")
return representations
'''
Encode Codebook and encoded features
(Don't modify)
'''
### CODE BOOK Make ####
print("Make Codebook ...")
flattened_normalized_train_features = pca.transform(flattened_train_features)
codebook = Codebook(K)
codebook.make_code_words(flattened_normalized_train_features)
train_encoded_features = list()
index = 0
for features, shapes in zip(train_normalized_features, train_feature_shapes):
encoded_features = codebook.encode(features, shapes)
train_encoded_features.append(encoded_features)
index += 1
print("Encoding Train Features ... {:4d}/{:4d}".format(index, len(train_normalized_features)))
test_encoded_features = list()
index = 0
for features, shapes in zip(test_normalized_features, test_feature_shapes):
encoded_features = codebook.encode(features, shapes)
test_encoded_features.append(encoded_features)
index += 1
print("Encoding Text Features ... {:4d}/{:4d}".format(index, len(test_normalized_features)))
import matplotlib.pyplot as plt
import numpy as np
# 시각화할 이미지 개수 (예: 24개)
num_show = 24
num_show = min(num_show, len(train_encoded_features))
plt.figure(figsize=(12, 10))
for i in range(num_show):
feat = np.asarray(train_encoded_features[i]) # shape: (K,)
label_idx = y_train[i] # 해당 이미지의 클래스 인덱스
label_name = labels_names[label_idx] # 클래스 이름
plt.subplot(4, 6, i + 1) # 4x6 그리드 (원하면 5x6 등으로 조정)
plt.bar(np.arange(len(feat)), feat) # BoF 히스토그램
plt.xticks([]) # x축 눈금 제거
plt.yticks([]) # y축 눈금 제거
plt.title(f"{label_name}({label_idx})", fontsize=8)
plt.tight_layout()
plt.show()
'''
Approximate Kernel for encoded features
(Don't modify)
'''
chi2sampler = AdditiveChi2Sampler(sample_steps=2)
chi2sampler.fit(train_encoded_features, y_train)
train_encoded_features = chi2sampler.transform(train_encoded_features)
test_encoded_features = chi2sampler.transform(test_encoded_features)
[문제 2. MLP 와 CNN 모델을 사용한 EuroSAT Classifier 학습 (35 pts)]
Pytorch 라이브러리를 사용하여 EuroSAT 데이터셋의 Classifier를 학습하세요. EuroSAT 데이터셋을
불러와 전처리를 진행하세요. Classifier는 MLP와 CNN 모델을 각각 구현한 후 학습을 시도해 보세
요. 손실 함수는 nn.CrossEntropyLoss()를 사용하고, 최적화 함수는 자유롭게 선택하세요
2-1. [데이터셋 전처리] EuroSAT 데이터셋을 불러와 각각 클래스의 이미지들을 확인해 보세요. 데이터셋을
torchvision.transforms을 사용하여 32*32 크기로 변형한 뒤, 이후 학습, 검증, 테스트 데이터로
분할하고 분할된 데이터셋의 크기를 확인해 보세요.
(https://pytorch.org/docs/stable/data.html, https://pytorch.org/vision/main/transforms.html 참고)
2-2. [MLP 모델 구현] nn.Linear 함수를 사용하여 3개 이상의 layer를 가진 MLP 모델을 구현하세요.
Layer 파라미터 설계는 자유롭게 진행해 보세요.
(https://pytorch.org/docs/stable/generated/torch.nn.Linear.html 참고)
2-3. [CNN 모델 구현] nn.Conv2d 함수를 사용하여 2개 이상의 layer를 가진 CNN 모델을 구현하
세요. Layer 파라미터 설계는 자유롭게 진행해 보세요. ConvNeXt와 같이 알려진 구조를 사용해도
되지만, torchvision.models.resnet 과 같이 사전에 구현된 pretrained 모델 구조를 그대로
불러오는 것은 안됩니다.
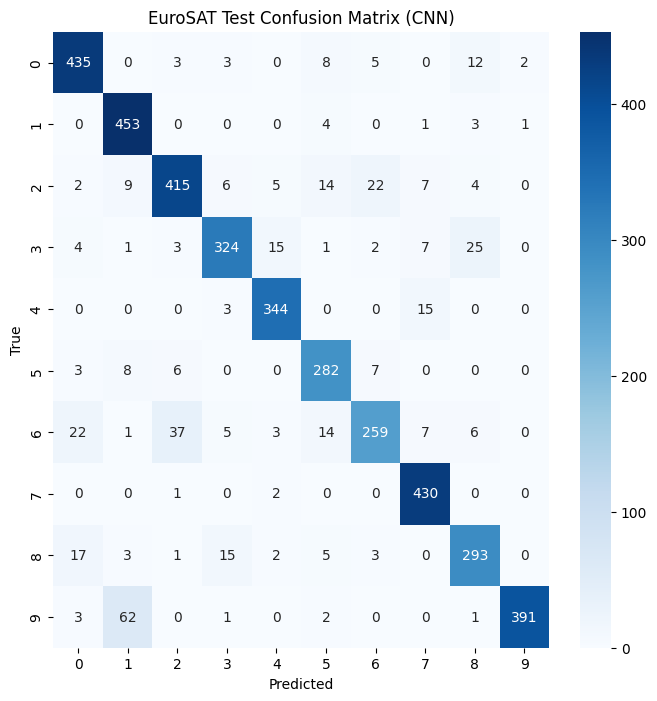
2-4. [결과 분석] 최적화 함수를 정의한 뒤 두 모델의 결과를 Train, Test 데이터셋에 각각에 대해
Accuracy와 Confusion Matrix를 통해 분석해보세요. 이 때 epoch 조정, learning rate 조정,
augmentation등의 추가 및 분석을 통해 더 나은 모델을 고르고, 선택된 모델이 더 좋은 성능을
보인 이유를 제시해 보세요. (분석 부재 시 감점)
- 기본 설정
- epoch: 50
- lr: 0.001
- augmentation: RandomHorizontalFlip + ColorJitter
- 실험 A: augmentation 제거
- 같은 epoch, lr에서 augmentation 없이 학습
- 결과: train acc ↑, test acc ↓라면 → 과적합 설명하기 좋음
- 실험 B: epoch 증가
- epoch: 100
- test acc 변화 비교 → 수렴/과적합 여부 분석
- 실험 C: learning rate 변화
- lr: 0.0005 vs 0.001 비교
- 수렴 속도, 최종 acc 비교
이 중 2~3개만 골라서 표로 정리해도 충분해.
리포트 문장 예시(대략적인 틀):
MLP와 CNN 모두 Adam(learning rate = 0.001, weight decay = 1e-4)을 사용하여 50 epoch 동안 학습하였다.
Augmentation을 적용하지 않은 경우 Train Accuracy는 증가했지만 Test Accuracy가 감소하여 과적합 경향을 보였다. 반면, RandomHorizontalFlip과 ColorJitter를 적용한 경우 Test Accuracy가 개선되었으며, 특히 CNN 모델에서 향상이 더 두드러졌다. 이는 CNN이 공간적 패턴을 더 잘 학습하는 특성상, 다양한 시각적 변형을 통해 일반화 성능이 향상된 것으로 해석할 수 있다.
4-4. “왜 CNN이 더 좋은지” 분석 포인트
실제 성능이 어떻게 나올지에 따라 내용은 조금 달라지겠지만, 보통:
- CNN Test Acc > MLP Test Acc일 가능성이 크니까, 이런 식으로 써주면 좋아:
- 공간 구조 학습
- MLP: 입력을 1D로 flatten해서 픽셀 간 공간 구조 정보 손실
- CNN: convolution + pooling으로 **지역적인 특징(패턴, 텍스처)**를 활용
- 파라미터 효율성
- 같은 수준의 표현력을 얻기 위해 MLP는 매우 많은 linear weight 필요
- CNN은 공유된 필터로 파라미터 수를 줄이면서도 복잡한 패턴 학습 가능
- Confusion Matrix 기반 해석
- 예: MLP는 특정 비슷한 토지 클래스끼리 자주 헷갈리는데, CNN에서는 혼동이 줄어든 경우
- “식생 패턴이나 토양 텍스처 등 지역적 패턴 차이를 CNN이 더 잘 포착한다”라고 연결
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.data.dataset import Subset
from torchvision.datasets import ImageFolder, utils
from torchvision.transforms import transforms
from sklearn.metrics import accuracy_score, confusion_matrix
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
#EuroSAT 데이터셋 다운로드 코드
def get_EuroSAT(dirname):
import os
if os.path.exists(dirname):
print("Dataset is already exist.")
return os.path.join(dirname, '2750')
os.makedirs(dirname, exist_ok=True)
utils.download_and_extract_archive(
"http://madm.dfki.de/files/sentinel/EuroSAT.zip",
download_root=dirname,
md5="c8fa014336c82ac7804f0398fcb19387",
remove_finished=True,
)
return os.path.join(dirname, '2750')
# GPU/CPU 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 데이터 전처리 및 로드
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.1, contrast=0.1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
dataset = ImageFolder(get_EuroSAT('EuroSAT'), transform=transform)
# 데이터셋 분할
dataset_size = len(dataset)
print('Dataset size:', dataset_size)
indices = list(range(dataset_size))
np.random.shuffle(indices)
split1 = int(np.floor(0.7 * dataset_size))
split2 = int(np.floor(0.85 * dataset_size))
train_indices = indices[:split1]
val_indices = indices[split1:split2]
test_indices = indices[split2:]
train_dataset = Subset(dataset, train_indices)
val_dataset = Subset(dataset, val_indices)
test_dataset = Subset(dataset, test_indices)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
print('Train loader size:', len(train_loader.dataset))
print('Val loader size:', len(val_loader.dataset))
print('Test loader size:', len(test_loader.dataset))
# MLP 정의
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layers = nn.Sequential(
nn.Linear(3*32*32, 1024),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(1024, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.layers(x)
return x
# CNN 정의
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 8 * 8, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 10)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
# 모델 선택
model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
# 학습 함수
def train(model, train_loader, optimizer, criterion):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
return running_loss / len(train_loader.dataset)
# 검증 함수
def validate(model, loader, criterion):
model.eval()
total_loss = 0.0
preds, trues = [], []
with torch.no_grad():
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
total_loss += loss.item() * inputs.size(0)
_, predicted = torch.max(outputs, 1)
preds.extend(predicted.cpu().numpy())
trues.extend(labels.cpu().numpy())
acc = accuracy_score(trues, preds)
cm = confusion_matrix(trues, preds)
return total_loss / len(loader.dataset), acc, cm
# 학습 실행
num_epochs = 100
for epoch in range(num_epochs):
train_loss = train(model, train_loader, optimizer, criterion)
val_loss, val_acc, _ = validate(model, val_loader, criterion)
print(f"Iter {epoch+1}/{num_epochs} | Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}")
# 테스트 평가
test_loss, test_acc, test_cm = validate(model, test_loader, criterion)
print(f"\nTest Accuracy: {test_acc:.4f}")
# Confusion Matrix 시각화 (파일 저장 + 화면 출력)
plt.figure(figsize=(8,8))
sns.heatmap(test_cm, annot=True, fmt="d", cmap="Blues")
plt.title("EuroSAT Test Confusion Matrix (CNN)")
plt.xlabel("Predicted")
plt.ylabel("True")
plt.savefig("EuroSAT_confusion_matrix.png")
plt.show()
plt.clf()
[문제 3. Instance Segmentation 모델 Fine-tuning (35 pts)]
Detectron2 라이브러리를 사용하여 사전 학습된 Mask R-CNN 모델을 불러와 풍선 데이터셋으로
fine-tuning 해보세요. 사전학습 모델은 Detectron2 Github에 정의된 모델 중 하나를 골라서 적용
해보세요.
3-1. [사전학습 모델 확인] 사전 학습된 모델을 불러와 예시 이미지에 적용하고 Segmentation이 잘
동작하는지 마스크를 시각화해서 확인해 보세요. 이때 해당 모델을 선정한 이유 (성능, inference
time)로 무엇을 고려했는지 언급해주셔야 합니다.
(https://github.com/facebookresearch/detectron2/blob/main/MODEL_ZOO.md 에서 백본 별 차이를 확인하시고,
https://github.com/facebookresearch/detectron2/tree/main/configs/COCO-InstanceSegmentation 참고하여 모델을
선택하세요)
3-2. [파인 튜닝] 템플릿 코드를 따라 풍선 데이터셋을 불러오고 train과 val을 확인해보세요. Train
데이터셋으로 segmentation 모델에 파인 튜닝을 진행하고, 이 모델을 val 데이터셋의 이미지들로
시각화해서 결과를 확인해 보세요.
3-3. [모델 검증] Detectron2.evaluation의 함수를 사용하여 파인 튜닝 전후 모델의 segmentation
mask에 대한 AP(Average Precision)과 AR(Average Recall)을 측정해 보세요. 여러 파라미터를
변경하여 진행한 결과를 보여주세요
(https://detectron2.readthedocs.io/en/latest/modules/evaluation.html#detectron2.evaluation.COCOEvaluator,
https://detectron2.readthedocs.io/en/latest/modules/evaluation.html#detectron2.evaluation.inference_on_dataset 참고)
3-4. [파인 튜닝 이후 문제] 3-1의 예시 이미지를 파인 튜닝이 끝난 모델에 적용하고 결과를
확인해보세요. 확인한 후 결과에서 보여지는 문제점의 이유에 대해서 분석하고 어떻게 해결할 수
있을지에 대해서 본인의 생각을 서술해주세요.
*hint : skeleton code의 fine-tuning하는 parameter등을 잘 살펴보세요
# ===============================
# 0. Detectron2 설치 + 데이터 다운로드
# ===============================
!pip install -q 'git+https://github.com/facebookresearch/detectron2.git'
# 예시 이미지 다운로드
!wget -q http://images.cocodataset.org/val2017/000000439715.jpg -O img_for_P3.jpg
# balloon dataset 다운로드 & 압축 해제
!wget -q https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
!unzip -qo balloon_dataset.zip # balloon/ 폴더 생김
# ===============================
# 1. 기본 세팅
# ===============================
import torch
TORCH_VERSION = ".".join(torch.__version__.split(".")[:2])
CUDA_VERSION = torch.__version__.split("+")[-1]
print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION)
import cv2
import warnings
warnings.filterwarnings(action='ignore')
import os
import json
import random
import numpy as np
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor, DefaultTrainer
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
from detectron2.structures import BoxMode
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using device:", device)
os.makedirs("./outputs_p3", exist_ok=True)
# ===============================
# 2. P3-1 사전학습 모델 선택 + 예시 이미지 추론
# ===============================
cfg = get_cfg()
# 모델 선택 (성능/속도 균형 좋은 ResNet-50 FPN 3x)
model_name = "COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"
cfg.merge_from_file(model_zoo.get_config_file(model_name))
cfg.MODEL.DEVICE = device
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name)
predictor = DefaultPredictor(cfg)
# 예시 이미지 추론 및 저장
img_path = "./img_for_P3.jpg"
save_path = "./outputs_p3/pretrained_pred.jpg"
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
assert img is not None, "예시 이미지를 먼저 다운로드하세요."
outputs = predictor(img)
# TRAIN 메타가 비어있을 수 있으므로 fallback 메타 사용
try:
meta_name = cfg.DATASETS.TRAIN[0]
metadata = MetadataCatalog.get(meta_name)
except Exception:
metadata = MetadataCatalog.get("__unused__")
v = Visualizer(img[:, :, ::-1], metadata, scale=1.2)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2.imwrite(save_path, out.get_image()[:, :, ::-1])
print(f"[P3-1] Pretrained inference saved to: {save_path}")
# ===============================
# 3. 풍선 데이터셋 로딩 함수 (Don't modify 부분)
# ===============================
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
# ===============================
# 4. 풍선 데이터셋 등록 + P3-1: pretrained 모델로 풍선 몇 장 시각화
# ===============================
for d in ["train", "val"]:
if "balloon_" + d in DatasetCatalog.list():
DatasetCatalog.remove("balloon_" + d)
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
dataset_dicts = get_balloon_dicts("balloon/train")
# 풍선 train 이미지 15장에 대해 pretrained 모델 결과 저장
os.makedirs("./outputs_p3/pretrained_balloon", exist_ok=True)
random.seed(1234)
for d in random.sample(dataset_dicts, min(15, len(dataset_dicts))):
im = cv2.imread(d["file_name"])
outputs = predictor(im)
v = Visualizer(
im[:, :, ::-1],
MetadataCatalog.get(cfg.DATASETS.TRAIN[0]) if len(cfg.DATASETS.TRAIN) > 0 else balloon_metadata,
scale=0.5
)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
filename = os.path.basename(d["file_name"])
save_path = f'./outputs_p3/pretrained_balloon/{filename}'
cv2.imwrite(save_path, out.get_image()[:, :, ::-1])
print("[P3-1] Pretrained model applied to some balloon/train images.")
# ===============================
# 5. P3-2,3 Fine-tuning 설정 + 학습
# ===============================
cfg_ft = get_cfg()
cfg_ft.merge_from_file(model_zoo.get_config_file(model_name))
cfg_ft.MODEL.DEVICE = device
cfg_ft.DATASETS.TRAIN = ("balloon_train",)
cfg_ft.DATASETS.TEST = ("balloon_val",)
cfg_ft.DATALOADER.NUM_WORKERS = 2
cfg_ft.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name) # COCO pretrained
cfg_ft.SOLVER.IMS_PER_BATCH = 2
cfg_ft.SOLVER.BASE_LR = 0.00025
cfg_ft.SOLVER.MAX_ITER = 600 # 과제에서 300~1000 사이 추천, 필요하면 조절
cfg_ft.SOLVER.STEPS = []
cfg_ft.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg_ft.MODEL.ROI_HEADS.NUM_CLASSES = 1 # balloon 1클래스
os.makedirs(cfg_ft.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg_ft)
trainer.resume_or_load(resume=False)
trainer.train()
# ===============================
# 6. P3-3 AP/AR 측정 (fine-tune 전/후 비교)
# ===============================
# 6-1. Fine-tuning 이전 (COCO pretrained 상태)
cfg_pre = get_cfg()
cfg_pre.merge_from_file(model_zoo.get_config_file(model_name))
cfg_pre.MODEL.DEVICE = device
cfg_pre.DATASETS.TEST = ("balloon_val",)
cfg_pre.DATALOADER.NUM_WORKERS = 2
cfg_pre.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name)
cfg_pre.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7
pre_predictor = DefaultPredictor(cfg_pre)
evaluator_pre = COCOEvaluator("balloon_val", cfg_pre, False, output_dir="./outputs_p3/eval_pre/")
val_loader_pre = build_detection_test_loader(cfg_pre, "balloon_val")
metrics_pre = inference_on_dataset(pre_predictor.model, val_loader_pre, evaluator_pre)
print("[P3-3] Pretrained model metrics on balloon_val:")
print(metrics_pre)
# 6-2. Fine-tuning 이후 (balloon에 맞게 학습된 모델)
cfg_ft.MODEL.WEIGHTS = os.path.join(cfg_ft.OUTPUT_DIR, "model_final.pth")
cfg_ft.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7
ft_predictor = DefaultPredictor(cfg_ft)
evaluator_ft = COCOEvaluator("balloon_val", cfg_ft, False, output_dir="./outputs_p3/eval_ft/")
val_loader_ft = build_detection_test_loader(cfg_ft, "balloon_val")
metrics_ft = inference_on_dataset(ft_predictor.model, val_loader_ft, evaluator_ft)
print("[P3-3] Fine-tuned model metrics on balloon_val:")
print(metrics_ft)
# ===============================
# 7. P3-2: Fine-tuned 모델로 balloon/val 시각화
# ===============================
os.makedirs("./outputs_p3/finetuned_vis", exist_ok=True)
val_dicts = get_balloon_dicts("balloon/val")
for d in random.sample(val_dicts, min(10, len(val_dicts))):
im = cv2.imread(d["file_name"])
outputs = ft_predictor(im)
v = Visualizer(im[:, :, ::-1], balloon_metadata, scale=0.5)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
filename = os.path.basename(d["file_name"])
cv2.imwrite(f'./outputs_p3/finetuned_vis/{filename}', out.get_image()[:, :, ::-1])
print("[P3-2] Fine-tuned model visualizations saved to ./outputs_p3/finetuned_vis")
# ===============================
# 8. P3-4: 예시 이미지에 fine-tuned 모델 재적용
# ===============================
ft_out_path = "./outputs_p3/finetuned_pred.jpg"
ft_outputs = ft_predictor(img)
v = Visualizer(img[:, :, ::-1], balloon_metadata, scale=1.2)
ft_draw = v.draw_instance_predictions(ft_outputs["instances"].to("cpu"))
cv2.imwrite(ft_out_path, ft_draw.get_image()[:, :, ::-1])
print(f"[P3-4] Fine-tuned inference saved to: {ft_out_path}")'개인 프로젝트 > 대학원 수업 정리' 카테고리의 다른 글
| [CV] 과제3_문제2 (0) | 2025.11.20 |
|---|---|
| [논문리뷰] CharGrid OCR 중요 원리 (0) | 2025.11.19 |
| [CV] 과제 3 (0) | 2025.11.12 |
| [과제2] Computer Vision 2 (3 - 1, 2) (0) | 2025.11.03 |
| [과제2] Computer Vision 2 (2 - 1, 2, 3) (0) | 2025.11.03 |




댓글