import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.data.dataset import Subset
from torchvision.datasets import ImageFolder, utils
from torchvision.transforms import transforms
from sklearn.metrics import accuracy_score, confusion_matrix
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
#EuroSAT 데이터셋 다운로드 코드
def get_EuroSAT(dirname):
import os
if os.path.exists(dirname):
print("Dataset is already exist.")
return os.path.join(dirname, '2750')
os.makedirs(dirname, exist_ok=True)
utils.download_and_extract_archive(
"http://madm.dfki.de/files/sentinel/EuroSAT.zip",
download_root=dirname,
md5="c8fa014336c82ac7804f0398fcb19387",
remove_finished=True,
)
return os.path.join(dirname, '2750')
# GPU/CPU 설정
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# 데이터 전처리 및 로드
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.1, contrast=0.1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
dataset = ImageFolder(get_EuroSAT('EuroSAT'), transform=transform)
# 데이터셋 분할
dataset_size = len(dataset)
print('Dataset size:', dataset_size)
indices = list(range(dataset_size))
np.random.shuffle(indices)
split1 = int(np.floor(0.7 * dataset_size))
split2 = int(np.floor(0.85 * dataset_size))
train_indices = indices[:split1]
val_indices = indices[split1:split2]
test_indices = indices[split2:]
train_dataset = Subset(dataset, train_indices)
val_dataset = Subset(dataset, val_indices)
test_dataset = Subset(dataset, test_indices)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
print('Train loader size:', len(train_loader.dataset))
print('Val loader size:', len(val_loader.dataset))
print('Test loader size:', len(test_loader.dataset))
# MLP 정의
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layers = nn.Sequential(
nn.Linear(3*32*32, 1024),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(1024, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.layers(x)
return x
# CNN 정의
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2),
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64 * 8 * 8, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 10)
)
def forward(self, x):
x = self.features(x)
x = self.classifier(x)
return x
# 모델 선택
model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4)
# 학습 함수
def train(model, train_loader, optimizer, criterion):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
return running_loss / len(train_loader.dataset)
# 검증 함수
def validate(model, loader, criterion):
model.eval()
total_loss = 0.0
preds, trues = [], []
with torch.no_grad():
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
total_loss += loss.item() * inputs.size(0)
_, predicted = torch.max(outputs, 1)
preds.extend(predicted.cpu().numpy())
trues.extend(labels.cpu().numpy())
acc = accuracy_score(trues, preds)
cm = confusion_matrix(trues, preds)
return total_loss / len(loader.dataset), acc, cm
# 학습 실행
num_epochs = 100
for epoch in range(num_epochs):
train_loss = train(model, train_loader, optimizer, criterion)
val_loss, val_acc, _ = validate(model, val_loader, criterion)
print(f"Iter {epoch+1}/{num_epochs} | Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}")
# 테스트 평가
test_loss, test_acc, test_cm = validate(model, test_loader, criterion)
print(f"\nTest Accuracy: {test_acc:.4f}")
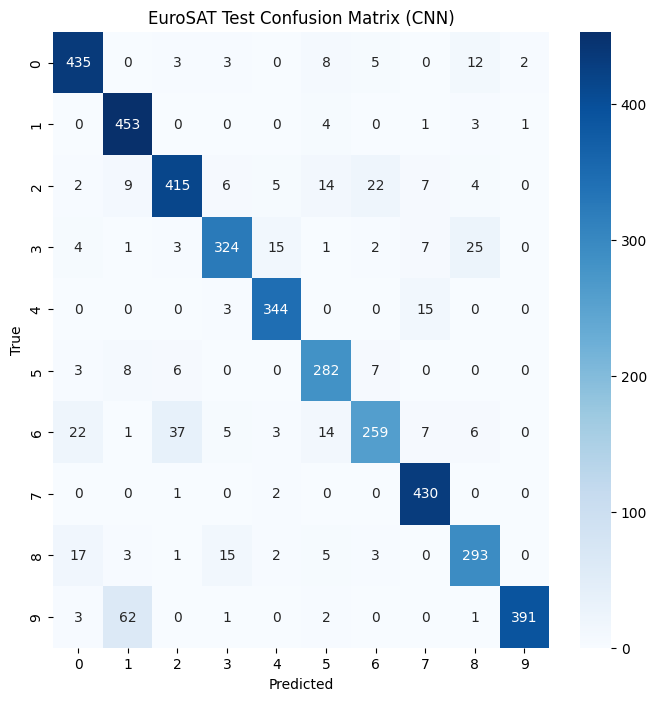
# Confusion Matrix 시각화 (파일 저장 + 화면 출력)
plt.figure(figsize=(8,8))
sns.heatmap(test_cm, annot=True, fmt="d", cmap="Blues")
plt.title("EuroSAT Test Confusion Matrix (CNN)")
plt.xlabel("Predicted")
plt.ylabel("True")
plt.savefig("EuroSAT_confusion_matrix.png")
plt.show()
plt.clf()1. 2-1. EuroSAT 전처리 요구사항 vs 지금 코드
문제 요구사항
- EuroSAT 데이터셋 불러오기
- 각 클래스 이미지 확인
- 32×32로 변형
- train/val/test 분할 후 각 크기 출력
네 코드
dataset = ImageFolder(get_EuroSAT('EuroSAT'), transform=transform)
dataset_size = len(dataset)
indices = list(range(dataset_size))
split1 = int(np.floor(0.7 * dataset_size))
split2 = int(np.floor(0.85 * dataset_size))
np.random.shuffle(indices)
train_indices, val_indices, test_indices = indices[:split1], indices[split1:split2], indices[split2:]
train_dataset = Subset(dataset, train_indices)
val_dataset = Subset(dataset, val_indices)
test_dataset = Subset(dataset, test_indices)
print('Train loader size:', len(train_loader.dataset))
print('Val loader size:', len(val_loader.dataset))
print('Test loader size:', len(test_loader.dataset))- ✅ EuroSAT 로드
- ✅ Resize(32, 32) 포함
- ✅ train/val/test 분할 + 크기 출력
- ✅ augmentation까지 사용(RandomHorizontalFlip, ColorJitter) → 리포트에 이유만 적어주면 됨.
딱 하나 더 하면 좋은 것:
“각 클래스의 이미지를 확인”하는 코드가 리포트에 들어가면 좋아.
예를 들어:
import matplotlib.pyplot as plt
class_names = dataset.classes
print("Classes:", class_names)
# 클래스당 1장씩 샘플 보기
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
axes = axes.flatten()
for cls_idx, cls_name in enumerate(class_names):
# 해당 클래스 인덱스 중 첫 번째 이미지
for i, (img, label) in enumerate(dataset):
if label == cls_idx:
axes[cls_idx].imshow(img.permute(1, 2, 0) * 0.5 + 0.5) # Normalize 복원
axes[cls_idx].set_title(cls_name)
axes[cls_idx].axis("off")
break
plt.tight_layout()
plt.savefig("EuroSAT_class_samples.png")
plt.close()2. 2-2. MLP 구현 – 요건 체크
요구사항
- nn.Linear를 사용한 3개 이상 layer
- 출력 차원 = 클래스 개수 (EuroSAT = 10)
네 코드
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.layers = nn.Sequential(
nn.Linear(3*32*32, 1024),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(1024, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
self.activation = nn.Softmax(dim=1) # 출력을 확률로 변환 (분석용)- ✅ Linear layer 3개 (input→1024, 1024→256, 256→10)
- ✅ 중간에 ReLU, Dropout도 있어서 구조 좋음
- ✅ 출력 10차원이라 EuroSAT(10 클래스)와도 일치
조금 더 깔끔하게 추천하는 수정
- 클래스 수를 하드코딩하지 말고, 데이터셋에서 자동으로 가져오기
num_classes = len(dataset.classes)
class MLP(nn.Module):
def __init__(self, num_classes):
super(MLP, self).__init__()
self.layers = nn.Sequential(
nn.Linear(3*32*32, 1024),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(1024, 256),
nn.ReLU(),
nn.Linear(256, num_classes)
)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.layers(x)
return x
# 사용시
mlp_model = MLP(num_classes).to(device)
2. self.activation = nn.Softmax(dim=1)는 CrossEntropyLoss 쓸 때는 안 쓰는 게 맞으니
- 그냥 제거하거나
- “분석 시 따로 softmax 씌운다” 정도로 리포트에만 언급하면 충분해.
3. 2-3. CNN 구현 – 요건 체크
요구사항
- nn.Conv2d를 사용한 2개 이상 layer
- 사전 구현 pretrained resnet은 사용 금지 (넌 안 쓰고 있어서 괜찮음)
네 코드
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2), # 32x32 → 16x16
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2), # 16x16 → 8x8
)
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64*8*8, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, 10)
)- ✅ Conv layer 2개 사용
- ✅ MaxPool로 공간 차원 줄이기
- ✅ FC + Dropout 구조
- 구조도 과제 조건에 충분히 맞음.
여기도 10 대신 num_classes 사용하면 더 일반적인 코드가 됨.
class CNN(nn.Module):
def __init__(self, num_classes):
super(CNN, self).__init__()
self.features = ...
self.classifier = nn.Sequential(
nn.Flatten(),
nn.Linear(64*8*8, 256),
nn.ReLU(),
nn.Dropout(0.4),
nn.Linear(256, num_classes)
)4. 2-4. 결과 분석 – 지금 상태 vs 채워야 할 부분
요구사항 요약
- 두 모델(MLP, CNN)에 대해
- Train Accuracy
- Test Accuracy
- Confusion Matrix
- epoch, learning rate, augmentation 변경 등 실험을 통해
- 성능 개선 시도
- “왜 이 모델이 더 좋았는지” 글로 분석
네 코드 현재 상태
def validate(model, data_loader, criterion):
...
val_accuracy = accuracy_score(all_labels, all_predictions)
val_confusion_matrix = confusion_matrix(all_labels, all_predictions)
return val_loss, val_accuracy, val_confusion_matrix- ✅ accuracy, confusion matrix 계산 함수 완성
- ✅ test set 에 대해:
test_loss, test_accuracy, test_confusion_matrix = validate(model, test_loader, criterion)
print(f"Test Accuracy: {test_accuracy:.4f}")
...
sns.heatmap(test_confusion_matrix, ...)→ CNN 하나에 대해서는 2-4의 절반 정도는 이미 충족하고 있어.
4-1. MLP도 같은 방식으로 학습/평가하기
과제에서 “두 모델을 비교”하라고 했으므로,
지금 구조에서 MLP 한 번, CNN 한 번 이렇게 돌려서 결과를 모아야 해.
예를 들어 이렇게 공통 함수를 하나 두고:
def run_experiment(model, train_loader, test_loader, num_epochs=50, lr=0.001, weight_decay=1e-4):
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=weight_decay)
for epoch in range(num_epochs):
train_loss = train(model, train_loader, optimizer, criterion)
test_loss, test_acc, _ = validate(model, test_loader, criterion)
print(f"[{model.__class__.__name__}] Epoch {epoch+1}/{num_epochs} | "
f"Train Loss: {train_loss:.4f} | Test Loss: {test_loss:.4f} | Test Acc: {test_acc:.4f}")
train_loss, train_acc, train_cm = validate(model, train_loader, criterion)
test_loss, test_acc, test_cm = validate(model, test_loader, criterion)
print(f"[{model.__class__.__name__}] FINAL | "
f"Train Acc: {train_acc:.4f} | Test Acc: {test_acc:.4f}")
return {
"model": model,
"train_acc": train_acc,
"test_acc": test_acc,
"train_cm": train_cm,
"test_cm": test_cm,
}
num_classes = len(dataset.classes)
mlp_result = run_experiment(MLP(num_classes), train_loader, test_loader,
num_epochs=50, lr=0.001)
cnn_result = run_experiment(CNN(num_classes), train_loader, test_loader,
num_epochs=50, lr=0.001)이렇게 하면:
- mlp_result["train_acc"], mlp_result["test_acc"]
- cnn_result["train_acc"], cnn_result["test_acc"]
- mlp_result["test_cm"], cnn_result["test_cm"]
을 표/그림으로 리포트에 정리하면 된다.
만약 교수님이 “Validation도 나눠라”라고 강조하셨으면, 위 함수에서 train/val/test 세 개 다 평가해도 됨.
(지금 네 코드처럼 train/val/test 셋 다 분리해 두었으니까 그대로 써도 상관없고.)
4-2. Confusion Matrix 시각화 (두 모델)
이미 CNN용으로는 heatmap을 만들었으니, MLP에도 같은 코드 쓰면 돼.
import matplotlib.pyplot as plt
class_names = dataset.classes
def plot_confusion_matrix(cm, class_names, title, filename):
hm = sns.heatmap(cm, annot=True, fmt="d", cmap="Blues",
xticklabels=class_names, yticklabels=class_names)
hm.set_xlabel("Predicted")
hm.set_ylabel("True")
hm.set_title(title)
hm.figure.savefig(filename)
hm.figure.clf()
plot_confusion_matrix(mlp_result["test_cm"], class_names,
"EuroSAT Test Confusion Matrix - MLP",
"EuroSAT_confusion_matrix_MLP.png")
plot_confusion_matrix(cnn_result["test_cm"], class_names,
"EuroSAT Test Confusion Matrix - CNN",
"EuroSAT_confusion_matrix_CNN.png")
이 두 이미지를 리포트에 나란히 놓고,
“어떤 클래스가 어디에서 더 헷갈리는지” 비교해서 설명해주면 돼.
4-3. epoch / lr / augmentation 변경 실험 아이디어
리포트에서 쓰기 좋은 실험 조합 예시:
- 기본 설정
- epoch: 50
- lr: 0.001
- augmentation: RandomHorizontalFlip + ColorJitter
- 실험 A: augmentation 제거
- 같은 epoch, lr에서 augmentation 없이 학습
- 결과: train acc ↑, test acc ↓라면 → 과적합 설명하기 좋음
- 실험 B: epoch 증가
- epoch: 100
- test acc 변화 비교 → 수렴/과적합 여부 분석
- 실험 C: learning rate 변화
- lr: 0.0005 vs 0.001 비교
- 수렴 속도, 최종 acc 비교
이 중 2~3개만 골라서 표로 정리해도 충분해.
리포트 문장 예시(대략적인 틀):
MLP와 CNN 모두 Adam(learning rate = 0.001, weight decay = 1e-4)을 사용하여 50 epoch 동안 학습하였다.
Augmentation을 적용하지 않은 경우 Train Accuracy는 증가했지만 Test Accuracy가 감소하여 과적합 경향을 보였다. 반면, RandomHorizontalFlip과 ColorJitter를 적용한 경우 Test Accuracy가 개선되었으며, 특히 CNN 모델에서 향상이 더 두드러졌다. 이는 CNN이 공간적 패턴을 더 잘 학습하는 특성상, 다양한 시각적 변형을 통해 일반화 성능이 향상된 것으로 해석할 수 있다.
4-4. “왜 CNN이 더 좋은지” 분석 포인트
실제 성능이 어떻게 나올지에 따라 내용은 조금 달라지겠지만, 보통:
- CNN Test Acc > MLP Test Acc일 가능성이 크니까, 이런 식으로 써주면 좋아:
- 공간 구조 학습
- MLP: 입력을 1D로 flatten해서 픽셀 간 공간 구조 정보 손실
- CNN: convolution + pooling으로 **지역적인 특징(패턴, 텍스처)**를 활용
- 파라미터 효율성
- 같은 수준의 표현력을 얻기 위해 MLP는 매우 많은 linear weight 필요
- CNN은 공유된 필터로 파라미터 수를 줄이면서도 복잡한 패턴 학습 가능
- Confusion Matrix 기반 해석
- 예: MLP는 특정 비슷한 토지 클래스끼리 자주 헷갈리는데, CNN에서는 혼동이 줄어든 경우
- “식생 패턴이나 토양 텍스처 등 지역적 패턴 차이를 CNN이 더 잘 포착한다”라고 연결
cpu
100%|██████████| 94.3M/94.3M [00:13<00:00, 7.18MB/s]
Dataset size: 27000
Train loader size: 18900
Val loader size: 4050
Test loader size: 4050
Iter 1/100 | Train Loss: 1.1574, Val Loss: 1.3121, Val Acc: 0.5916
Iter 2/100 | Train Loss: 0.8618, Val Loss: 0.7891, Val Acc: 0.7210
Iter 3/100 | Train Loss: 0.7659, Val Loss: 0.8980, Val Acc: 0.6909
Iter 4/100 | Train Loss: 0.7183, Val Loss: 0.6236, Val Acc: 0.7664
Iter 5/100 | Train Loss: 0.6573, Val Loss: 0.5613, Val Acc: 0.8074
Iter 6/100 | Train Loss: 0.6239, Val Loss: 0.6951, Val Acc: 0.7647
Iter 7/100 | Train Loss: 0.5874, Val Loss: 0.6233, Val Acc: 0.7654
Iter 8/100 | Train Loss: 0.5630, Val Loss: 0.5001, Val Acc: 0.8222
Iter 9/100 | Train Loss: 0.5278, Val Loss: 0.4473, Val Acc: 0.8417
Iter 10/100 | Train Loss: 0.5081, Val Loss: 0.4830, Val Acc: 0.8249
Iter 11/100 | Train Loss: 0.4825, Val Loss: 0.6129, Val Acc: 0.7975
Iter 12/100 | Train Loss: 0.4640, Val Loss: 0.4656, Val Acc: 0.8316
Iter 13/100 | Train Loss: 0.4375, Val Loss: 0.4409, Val Acc: 0.8368
Iter 14/100 | Train Loss: 0.4210, Val Loss: 0.5552, Val Acc: 0.7975
Iter 15/100 | Train Loss: 0.4072, Val Loss: 0.4285, Val Acc: 0.8459
Iter 16/100 | Train Loss: 0.3936, Val Loss: 0.4282, Val Acc: 0.8457
Iter 17/100 | Train Loss: 0.3786, Val Loss: 0.4016, Val Acc: 0.8585
Iter 18/100 | Train Loss: 0.3665, Val Loss: 0.4862, Val Acc: 0.8301
Iter 19/100 | Train Loss: 0.3620, Val Loss: 0.6321, Val Acc: 0.7798
Iter 20/100 | Train Loss: 0.3425, Val Loss: 0.3592, Val Acc: 0.8751
Iter 21/100 | Train Loss: 0.3273, Val Loss: 0.3876, Val Acc: 0.8733
Iter 22/100 | Train Loss: 0.3226, Val Loss: 0.5315, Val Acc: 0.8074
Iter 23/100 | Train Loss: 0.3036, Val Loss: 1.1252, Val Acc: 0.7244
Iter 24/100 | Train Loss: 0.3086, Val Loss: 0.6023, Val Acc: 0.8104
Iter 25/100 | Train Loss: 0.3101, Val Loss: 0.5070, Val Acc: 0.8257
Iter 26/100 | Train Loss: 0.2851, Val Loss: 0.4469, Val Acc: 0.8407
Iter 27/100 | Train Loss: 0.2857, Val Loss: 0.3410, Val Acc: 0.8872
Iter 28/100 | Train Loss: 0.2687, Val Loss: 0.5297, Val Acc: 0.8240
Iter 29/100 | Train Loss: 0.2636, Val Loss: 0.7486, Val Acc: 0.7960
Iter 30/100 | Train Loss: 0.2489, Val Loss: 0.6071, Val Acc: 0.7800
Iter 31/100 | Train Loss: 0.2604, Val Loss: 0.3316, Val Acc: 0.8916
Iter 32/100 | Train Loss: 0.2409, Val Loss: 0.3248, Val Acc: 0.8933
Iter 33/100 | Train Loss: 0.2459, Val Loss: 0.3625, Val Acc: 0.8793
Iter 34/100 | Train Loss: 0.2239, Val Loss: 0.3846, Val Acc: 0.8679
Iter 35/100 | Train Loss: 0.2193, Val Loss: 0.3980, Val Acc: 0.8716
Iter 36/100 | Train Loss: 0.2096, Val Loss: 0.3347, Val Acc: 0.8919
Iter 37/100 | Train Loss: 0.2104, Val Loss: 0.4770, Val Acc: 0.8333
Iter 38/100 | Train Loss: 0.2173, Val Loss: 0.5457, Val Acc: 0.8430
Iter 39/100 | Train Loss: 0.2122, Val Loss: 0.3298, Val Acc: 0.8906
Iter 40/100 | Train Loss: 0.2012, Val Loss: 0.3143, Val Acc: 0.8978
Iter 41/100 | Train Loss: 0.2001, Val Loss: 0.5331, Val Acc: 0.8296
Iter 42/100 | Train Loss: 0.2017, Val Loss: 0.3942, Val Acc: 0.8746
Iter 43/100 | Train Loss: 0.1840, Val Loss: 0.7336, Val Acc: 0.7790
Iter 44/100 | Train Loss: 0.1828, Val Loss: 0.3568, Val Acc: 0.8867
Iter 45/100 | Train Loss: 0.1807, Val Loss: 0.4294, Val Acc: 0.8635
Iter 46/100 | Train Loss: 0.1851, Val Loss: 0.5678, Val Acc: 0.8351
Iter 47/100 | Train Loss: 0.1716, Val Loss: 0.4054, Val Acc: 0.8667
Iter 48/100 | Train Loss: 0.1841, Val Loss: 0.4352, Val Acc: 0.8664
Iter 49/100 | Train Loss: 0.1749, Val Loss: 0.4068, Val Acc: 0.8686
Iter 50/100 | Train Loss: 0.1618, Val Loss: 0.3890, Val Acc: 0.8820
Iter 51/100 | Train Loss: 0.1675, Val Loss: 0.3622, Val Acc: 0.8911
Iter 52/100 | Train Loss: 0.1599, Val Loss: 0.3926, Val Acc: 0.8825
Iter 53/100 | Train Loss: 0.1607, Val Loss: 0.4057, Val Acc: 0.8726
Iter 54/100 | Train Loss: 0.1576, Val Loss: 0.3819, Val Acc: 0.8854
Iter 55/100 | Train Loss: 0.1535, Val Loss: 0.3238, Val Acc: 0.8990
Iter 56/100 | Train Loss: 0.1513, Val Loss: 0.4554, Val Acc: 0.8615
Iter 57/100 | Train Loss: 0.1506, Val Loss: 0.5139, Val Acc: 0.8284
Iter 58/100 | Train Loss: 0.1440, Val Loss: 0.3244, Val Acc: 0.9064
Iter 59/100 | Train Loss: 0.1447, Val Loss: 0.4046, Val Acc: 0.8758
Iter 60/100 | Train Loss: 0.1385, Val Loss: 0.4777, Val Acc: 0.8649
Iter 61/100 | Train Loss: 0.1469, Val Loss: 0.5753, Val Acc: 0.8346
Iter 62/100 | Train Loss: 0.1396, Val Loss: 0.3865, Val Acc: 0.8901
Iter 63/100 | Train Loss: 0.1480, Val Loss: 0.3790, Val Acc: 0.8911
Iter 64/100 | Train Loss: 0.1387, Val Loss: 0.3309, Val Acc: 0.9020
Iter 65/100 | Train Loss: 0.1359, Val Loss: 0.7523, Val Acc: 0.7842
Iter 66/100 | Train Loss: 0.1331, Val Loss: 0.5552, Val Acc: 0.8435
Iter 67/100 | Train Loss: 0.1309, Val Loss: 0.4437, Val Acc: 0.8728
Iter 68/100 | Train Loss: 0.1254, Val Loss: 0.5102, Val Acc: 0.8484
Iter 69/100 | Train Loss: 0.1244, Val Loss: 0.3554, Val Acc: 0.9022
Iter 70/100 | Train Loss: 0.1262, Val Loss: 0.3538, Val Acc: 0.8975
Iter 71/100 | Train Loss: 0.1344, Val Loss: 0.3825, Val Acc: 0.8832
Iter 72/100 | Train Loss: 0.1285, Val Loss: 0.5789, Val Acc: 0.8457
Iter 73/100 | Train Loss: 0.1187, Val Loss: 0.3362, Val Acc: 0.8983
Iter 74/100 | Train Loss: 0.1247, Val Loss: 0.3818, Val Acc: 0.8844
Iter 75/100 | Train Loss: 0.1289, Val Loss: 0.3736, Val Acc: 0.8926
Iter 76/100 | Train Loss: 0.1274, Val Loss: 0.4280, Val Acc: 0.8738
Iter 77/100 | Train Loss: 0.1132, Val Loss: 0.3598, Val Acc: 0.9005
Iter 78/100 | Train Loss: 0.1138, Val Loss: 0.5023, Val Acc: 0.8519
Iter 79/100 | Train Loss: 0.1210, Val Loss: 0.4170, Val Acc: 0.8748
Iter 80/100 | Train Loss: 0.1209, Val Loss: 0.3458, Val Acc: 0.8973
Iter 81/100 | Train Loss: 0.1148, Val Loss: 0.4364, Val Acc: 0.8758
Iter 82/100 | Train Loss: 0.1254, Val Loss: 0.3985, Val Acc: 0.8825
Iter 83/100 | Train Loss: 0.1135, Val Loss: 0.5341, Val Acc: 0.8454
Iter 84/100 | Train Loss: 0.1145, Val Loss: 0.3979, Val Acc: 0.8864
Iter 85/100 | Train Loss: 0.1149, Val Loss: 0.3699, Val Acc: 0.8914
Iter 86/100 | Train Loss: 0.1137, Val Loss: 0.4282, Val Acc: 0.8867
Iter 87/100 | Train Loss: 0.1149, Val Loss: 0.3833, Val Acc: 0.8956
Iter 88/100 | Train Loss: 0.1140, Val Loss: 0.4421, Val Acc: 0.8763
Iter 89/100 | Train Loss: 0.1150, Val Loss: 0.4744, Val Acc: 0.8610
Iter 90/100 | Train Loss: 0.1141, Val Loss: 0.3854, Val Acc: 0.8753
Iter 91/100 | Train Loss: 0.1032, Val Loss: 0.3560, Val Acc: 0.8921
Iter 92/100 | Train Loss: 0.1047, Val Loss: 0.3240, Val Acc: 0.9059
Iter 93/100 | Train Loss: 0.1034, Val Loss: 0.6194, Val Acc: 0.8425
Iter 94/100 | Train Loss: 0.1044, Val Loss: 0.5045, Val Acc: 0.8578
Iter 95/100 | Train Loss: 0.1066, Val Loss: 0.4747, Val Acc: 0.8647
Iter 96/100 | Train Loss: 0.1052, Val Loss: 0.5532, Val Acc: 0.8689
Iter 97/100 | Train Loss: 0.1031, Val Loss: 0.4675, Val Acc: 0.8637
Iter 98/100 | Train Loss: 0.1044, Val Loss: 0.3890, Val Acc: 0.8970
Iter 99/100 | Train Loss: 0.1081, Val Loss: 0.4733, Val Acc: 0.8617
Iter 100/100 | Train Loss: 0.0967, Val Loss: 0.4028, Val Acc: 0.8889
Test Accuracy: 0.8953
'개인 프로젝트 > 대학원 수업 정리' 카테고리의 다른 글
| [CV] Classification, Segmentation (0) | 2025.12.02 |
|---|---|
| [CV] 과제3_3번 (0) | 2025.11.20 |
| [논문리뷰] CharGrid OCR 중요 원리 (0) | 2025.11.19 |
| [CV] 과제 3 최종코드 (0) | 2025.11.16 |
| [CV] 과제 3 (0) | 2025.11.12 |



댓글