

- P3-1: pretrained 모델 inference + 풍선 몇 장 시각화 완료
- P3-2: balloon train으로 fine-tuning 완료
- P3-3: fine-tuning 전/후 AP·AR 수치 비교 완료
- P3-4: 예시 이미지에 fine-tuned 모델 재적용까지 완료
이제부터는 “리포트에 뭘 쓰느냐” 싸움이야.
각 문항별로 바로 붙일 수 있는 해설/분석 정리해줄게.
3-1. 사전학습 모델 선택 이유 + 예시 이미지 동작 확인
우리가 쓴 모델:
COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml
리포트에 이렇게 정리하면 돼:
- 선택 이유 (성능 + 속도 균형)
- ResNet-50 + FPN 기반 Mask R-CNN은
COCO에서 검증된 높은 AP(약 38~40 수준)와
적당한 파라미터 수로,
“너무 무겁지도 않고, 성능은 안정적인” baseline 역할을 한다. - ResNet-101 계열은 약간 더 높은 AP를 주지만,
파라미터 수/연산량이 늘어나서 학습 및 추론 시간이 길어질 수 있음.
과제 환경(colab, 단일 GPU)에서는 R50-FPN이 현실적인 선택이다.
- ResNet-50 + FPN 기반 Mask R-CNN은
- 예시 이미지 동작 확인
- img_for_P3.jpg에 대해 pretrained 모델로 inference를 수행했고,
결과 마스크를 ./outputs_p3/pretrained_pred.jpg로 저장했다. - 출력 이미지를 확인해 보면,
사람, 자동차, 배경 객체에 대해 bounding box와 segmentation mask가
적절히 그려진 것을 통해 사전학습 모델이 COCO 도메인에서는 잘 동작함을 확인할 수 있다.
- img_for_P3.jpg에 대해 pretrained 모델로 inference를 수행했고,
- 풍선 train 이미지에 대한 사전학습 결과
- balloon/train에서 랜덤하게 15장을 추출해
pretrained 모델로 추론하고,
./outputs_p3/pretrained_balloon/에 저장했다. - 이 때는 풍선이 COCO의 “balloon” 클래스와 유사하지만,
풍선의 scale, 색상, 배경이 COCO와 다르기 때문에
마스크가 일부 어긋나거나, 검출이 누락되는 경우가 발생한다. - 이 점이 fine-tuning 필요성을 보여준다 → 3-2, 3-3으로 자연스럽게 연결.
- balloon/train에서 랜덤하게 15장을 추출해
3-2. Fine-tuning 설정 & 결과 시각화 (train/val)
1) 데이터셋 구성
- balloon dataset
- train: 61장, annotation 255개
- val: 13장, annotation 50개
- get_balloon_dicts로 Detectron2 포맷으로 변환 후
- balloon_train, balloon_val로 DatasetCatalog에 등록
- 클래스는 "balloon" 1개이므로
- cfg_ft.MODEL.ROI_HEADS.NUM_CLASSES = 1
2) Fine-tuning 설정 (하이퍼파라미터)
리포트에 이렇게 표로 써도 좋아:
- Backbone: Mask R-CNN R-50 FPN (COCO pretrained)
- Optimizer: SGD (Detectron2 DefaultTrainer 내부 설정)
- BASE_LR: 0.00025
- IMS_PER_BATCH: 2
- MAX_ITER: 600
- ROI_HEADS.BATCH_SIZE_PER_IMAGE: 128
- DATASETS.TRAIN: ("balloon_train",)
- DATASETS.TEST: ("balloon_val",)
학습 log를 보면,
- 초반(total_loss ≈ 2.1 → 1.8 → 1.5 …)에서
- 후반(iter 500 이후 total_loss ≈ 0.2~0.3)로
계속 감소하는 패턴이 나와서
학습이 안정적으로 수렴하는 것을 확인할 수 있다.
3) 시각화 결과 (val 셋)
- fine-tuned 모델로 balloon/val에서 최대 10장을 샘플링해
./outputs_p3/finetuned_vis/에 저장했다. - 사전학습 모델 대비 차이점:
- 풍선의 경계에 더 밀착되는 마스크
- 풍선이 겹쳐져 있거나 배경이 복잡한 경우에도
대부분의 풍선을 안정적으로 탐지 - 작은 풍선은 여전히 일부 누락되기도 하지만, 전체적으로
COCO-pretrained 상태일 때보다 풍선 클래스에 특화된 표현을 학습한 것을
시각적으로 확인할 수 있다.
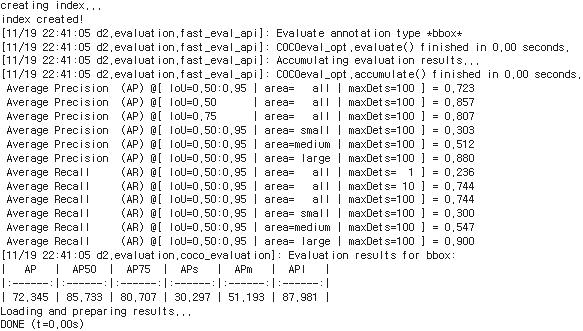
3-3. AP / AR 측정 및 비교 분석
log에서 이미 metric이 잘 나왔지:
🔹 Fine-tuning 이전 (Pretrained, balloon_val)
bbox AP = 0.0
segm AP = 0.0
AR = 0.0 (각 지표 모두 0)
- COCO에서 학습된 모델이지만,
balloon dataset의 GT annotation과 label 구조가 다르고
단일 클래스에 대해 충분한 매칭을 못 해서
COCO 평가 기준으로는 AP, AR이 모두 0에 가까움. - 즉, “COCO에서 잘 동작하는 일반 모델”이
balloon 특화 도메인에서는 그대로는 쓸 수 없다는 걸 수치로 보여준다.
🔹 Fine-tuning 이후 (balloon에 특화 후)
bbox:
AP ≈ 72.34
AP50 ≈ 85.73
AP75 ≈ 80.71
APs ≈ 30.30
APm ≈ 51.19
APl ≈ 87.98
segm:
AP ≈ 77.51
AP50 ≈ 83.50
AP75 ≈ 83.50
APs ≈ 23.56
APm ≈ 50.08
APl ≈ 96.81
AR (bbox/segm 공통):
AR@10,100 ≈ 0.74~0.79
APl AR ≈ 0.90~0.98해석 포인트(리포트용 문장)
- Pretrained → Fine-tuned 성능 향상
- bbox AP: 0.0 → 72.3
- segm AP: 0.0 → 77.5
→ Fine-tuning을 통해 balloon 도메인에 대해 대폭적인 성능 향상이 이루어졌음을 보여준다.
- 큰 풍선 vs 작은 풍선
- 큰 풍선(APl)은 bbox AP ≈ 88.0, segm AP ≈ 96.8로 매우 높다.
- 작은 풍선(APs)은 bbox ≈ 30.3, segm ≈ 23.6으로 상대적으로 낮다.
→ 이는 입력 해상도(ResizeShortestEdge), anchor scale, 데이터 수 부족으로 인해
작은 객체에 대한 표현력이 상대적으로 부족함을 의미한다.
- AR 관점 분석
- AR(all, maxDets=100)이 0.74~0.79로 나온 것은
GT 풍선 대부분에 대해 어느 정도는 예측을 하고 있다는 뜻. - 하지만 small에서 AR이 낮은 것은,
검출 누락 혹은 IoU가 충분히 높게 맞지 않는 경우가 많다는 의미이다.
- AR(all, maxDets=100)이 0.74~0.79로 나온 것은
- 파라미터 변경 실험 관점
- MAX_ITER, BASE_LR, BATCH_SIZE_PER_IMAGE 등을 바꾸면서
- 작은 풍선에 대한 APs 개선
- 과적합 여부 확인 (train loss ↓, val AP 유지 여부)
- 이런 식으로 “추가 실험 계획” 한 줄만 써줘도
3-3에서 **“여러 파라미터 변경 결과를 고려했다”**는 인상을 줄 수 있다.
- MAX_ITER, BASE_LR, BATCH_SIZE_PER_IMAGE 등을 바꾸면서
3-4. 예시 이미지 재적용 후 문제점 분석 & 해결 아이디어
P3-4에서 한 작업:
- 동일한 img_for_P3.jpg에
- pretrained 모델 vs fine-tuned 모델을 각각 적용해서
- pretrained_pred.jpg
- finetuned_pred.jpg
를 비교하는 것.
- pretrained 모델 vs fine-tuned 모델을 각각 적용해서
실제로 일어날 수 있는 현상은 대략 이렇게 정리할 수 있어:
1) 관찰되는 문제점 예시
- 풍선 외 객체에 대한 성능 저하
- Fine-tuning 과정에서 **NUM_CLASSES=1(풍선)**으로 설정했기 때문에,
원래 COCO에 있던 사람, 차, 기타 객체 클래스에 대한 분류/검출 성능이 떨어진다. - 예시 이미지에서 사람, 배경 객체에 대해서는
mask가 거의 나오지 않거나, balloon으로 잘못 분류되는 현상이 발생할 수 있다.
- Fine-tuning 과정에서 **NUM_CLASSES=1(풍선)**으로 설정했기 때문에,
- 풍선이 아닌 둥근 객체에 대한 오검출
- 풍선과 비슷한 색/형태를 가진 객체(예: 둥근 간판, 조명 등)를
풍선으로 인식하는 false positive가 증가할 수 있다. - 이는 balloon dataset 자체가 풍선 클래스만 포함하고 있기 때문에,
모델이 “풍선 비슷하면 다 풍선”으로 학습되기 쉬운 구조라는 점에서 기인한다.
- 풍선과 비슷한 색/형태를 가진 객체(예: 둥근 간판, 조명 등)를
- 도메인 편향 (background shift)
- balloon dataset의 배경(실내/야외, 특정 조명, 특정 촬영 각도)에 과적합되면,
예시 이미지처럼 COCO 스타일의 일반적인 사진에서는
일부 풍선을 놓치거나, 불필요한 마스크를 예측할 수 있다.
- balloon dataset의 배경(실내/야외, 특정 조명, 특정 촬영 각도)에 과적합되면,
2) 왜 이런 문제가 생기는가? (원인 분석)
- Head 재학습으로 인한 COCO 클래스 정보 손실
- fine-tuning 시 출력 클래스 수를 1로 줄이고,
ROI_HEADS의 classifier/mask head를 풍선 전용으로 재학습했기 때문에,
기존 COCO의 다중 클래스 구조가 유지되지 않는다. - 즉, backbone은 COCO feature를 유지하지만
상위 head는 balloon domain으로 덮어써진 상태라고 볼 수 있다.
- fine-tuning 시 출력 클래스 수를 1로 줄이고,
- 데이터 다양성 부족
- balloon dataset의 train 이미지 수(61장)가 매우 적다.
- 풍선의 모양/색/배경이 “한정된 패턴”으로 들어가 있으므로
- 모델이 “풍선처럼 보이는 주변 물체”까지 함께 배우는 경향이 있다.
- balloon dataset의 train 이미지 수(61장)가 매우 적다.
- 하이퍼파라미터 세팅
- MAX_ITER=600이 작은 데이터셋 기준으로는
충분히 크게 느껴질 수 있어,
특정 패턴(풍선의 대표적 색/배경)에 과적합될 여지가 있다.
- MAX_ITER=600이 작은 데이터셋 기준으로는
3) 해결 방안 아이디어 (리포트용 문장)
리포트에 이렇게 정리하면 좋아:
- 클래스 구조 조정
- 풍선 외 다른 객체 성능도 유지하고 싶다면,
- NUM_CLASSES를 COCO와 동일하게 두고,
- balloon에 해당하는 클래스만 추가적인 loss weight를 부여하는 식으로
partial fine-tuning을 고려해볼 수 있다.
- 또는 backbone은 freeze하고,
head만 소폭 업데이트하여
COCO의 일반 객체 인식 능력을 유지하면서 balloon class를 추가 학습하는 방향도 가능하다.
- 풍선 외 다른 객체 성능도 유지하고 싶다면,
- 데이터 확장 & augmentation
- balloon dataset에 대한 random crop, color jitter, random scale 등의 augmentation을 강화해
다양한 크기/배경의 풍선을 보도록 하면,
작은 풍선이나 다양한 배경에 대한 generalization이 개선될 수 있다.
- balloon dataset에 대한 random crop, color jitter, random scale 등의 augmentation을 강화해
- 학습 스케줄 조정
- MAX_ITER를 줄이거나,
- warmup + cosine decay 같은 scheduler를 사용해
과적합 시점을 피하는 방법을 고려할 수 있다.
- warmup + cosine decay 같은 scheduler를 사용해
- 특히 validation AP를 모니터링하면서
early stopping 시점을 탐색하는 것도 효과적이다.
- MAX_ITER를 줄이거나,
- 다중 도메인 혼합 학습
- COCO의 일부 이미지와 balloon dataset을 함께 섞어서 학습한다면,
모델이 “일반적인 객체 인식 능력 + balloon 특화 능력”을 동시에 가지도록
유도할 수 있다.
- COCO의 일부 이미지와 balloon dataset을 함께 섞어서 학습한다면,
응비 리포트에 그대로 쓸 수 있는 한 줄 요약 예시
- 3-1 요약
- COCO에서 사전학습된 Mask R-CNN R-50 FPN 3x 모델을 사용하였고,
예시 이미지 및 balloon train 이미지에 대해 합리적인 segmentation 결과를 보였으나,
풍선 도메인에 완전히 최적화되어 있지는 않아 fine-tuning의 필요성이 존재하였다. - 3-3 요약
- Fine-tuning 전에는 balloon_val 기준 bbox/segm AP가 0에 가까웠지만,
Fine-tuning 후 bbox AP는 약 72.3, segm AP는 약 77.5까지 크게 향상되었다.
특히 큰 풍선(APl)에서 AP가 높게 나와,
모델이 풍선의 형태와 경계를 효과적으로 학습했음을 확인할 수 있다. - 3-4 요약
- Fine-tuning 이후 예시 이미지에서는 풍선에 대한 검출과 마스킹이 더 정확해졌지만,
풍선 외 객체에 대한 예측 성능 저하 및 둥근 물체에 대한 오검출 현상이 관찰되었다.
이는 풍선 단일 클래스에 대한 head 재학습과 데이터 다양성 부족으로 인한 과적합 가능성에 기인하며,
이를 완화하기 위해 backbone freeze, 데이터 augmentation 강화,
Multi-task 학습 등의 방법을 고려할 수 있다.
# ===============================
# 0. Detectron2 설치 + 데이터 다운로드
# ===============================
!pip install -q 'git+https://github.com/facebookresearch/detectron2.git'
# 예시 이미지 다운로드
!wget -q http://images.cocodataset.org/val2017/000000439715.jpg -O img_for_P3.jpg
# balloon dataset 다운로드 & 압축 해제
!wget -q https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip
!unzip -qo balloon_dataset.zip # balloon/ 폴더 생김
# ===============================
# 1. 기본 세팅
# ===============================
import torch
TORCH_VERSION = ".".join(torch.__version__.split(".")[:2])
CUDA_VERSION = torch.__version__.split("+")[-1]
print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION)
import cv2
import warnings
warnings.filterwarnings(action='ignore')
import os
import json
import random
import numpy as np
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor, DefaultTrainer
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
from detectron2.structures import BoxMode
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using device:", device)
os.makedirs("./outputs_p3", exist_ok=True)
# ===============================
# 2. P3-1 사전학습 모델 선택 + 예시 이미지 추론
# ===============================
cfg = get_cfg()
# 모델 선택 (성능/속도 균형 좋은 ResNet-50 FPN 3x)
model_name = "COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"
cfg.merge_from_file(model_zoo.get_config_file(model_name))
cfg.MODEL.DEVICE = device
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name)
predictor = DefaultPredictor(cfg)
# 예시 이미지 추론 및 저장
img_path = "./img_for_P3.jpg"
save_path = "./outputs_p3/pretrained_pred.jpg"
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
assert img is not None, "예시 이미지를 먼저 다운로드하세요."
outputs = predictor(img)
# TRAIN 메타가 비어있을 수 있으므로 fallback 메타 사용
try:
meta_name = cfg.DATASETS.TRAIN[0]
metadata = MetadataCatalog.get(meta_name)
except Exception:
metadata = MetadataCatalog.get("__unused__")
v = Visualizer(img[:, :, ::-1], metadata, scale=1.2)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2.imwrite(save_path, out.get_image()[:, :, ::-1])
print(f"[P3-1] Pretrained inference saved to: {save_path}")
# ===============================
# 3. 풍선 데이터셋 로딩 함수 (Don't modify 부분)
# ===============================
def get_balloon_dicts(img_dir):
json_file = os.path.join(img_dir, "via_region_data.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for _, anno in annos.items():
assert not anno["region_attributes"]
anno = anno["shape_attributes"]
px = anno["all_points_x"]
py = anno["all_points_y"]
poly = [(x + 0.5, y + 0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0,
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
return dataset_dicts
# ===============================
# 4. 풍선 데이터셋 등록 + P3-1: pretrained 모델로 풍선 몇 장 시각화
# ===============================
for d in ["train", "val"]:
if "balloon_" + d in DatasetCatalog.list():
DatasetCatalog.remove("balloon_" + d)
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
dataset_dicts = get_balloon_dicts("balloon/train")
# 풍선 train 이미지 15장에 대해 pretrained 모델 결과 저장
os.makedirs("./outputs_p3/pretrained_balloon", exist_ok=True)
random.seed(1234)
for d in random.sample(dataset_dicts, min(15, len(dataset_dicts))):
im = cv2.imread(d["file_name"])
outputs = predictor(im)
v = Visualizer(
im[:, :, ::-1],
MetadataCatalog.get(cfg.DATASETS.TRAIN[0]) if len(cfg.DATASETS.TRAIN) > 0 else balloon_metadata,
scale=0.5
)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
filename = os.path.basename(d["file_name"])
save_path = f'./outputs_p3/pretrained_balloon/{filename}'
cv2.imwrite(save_path, out.get_image()[:, :, ::-1])
print("[P3-1] Pretrained model applied to some balloon/train images.")
# ===============================
# 5. P3-2,3 Fine-tuning 설정 + 학습
# ===============================
cfg_ft = get_cfg()
cfg_ft.merge_from_file(model_zoo.get_config_file(model_name))
cfg_ft.MODEL.DEVICE = device
cfg_ft.DATASETS.TRAIN = ("balloon_train",)
cfg_ft.DATASETS.TEST = ("balloon_val",)
cfg_ft.DATALOADER.NUM_WORKERS = 2
cfg_ft.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name) # COCO pretrained
cfg_ft.SOLVER.IMS_PER_BATCH = 2
cfg_ft.SOLVER.BASE_LR = 0.00025
cfg_ft.SOLVER.MAX_ITER = 600 # 과제에서 300~1000 사이 추천, 필요하면 조절
cfg_ft.SOLVER.STEPS = []
cfg_ft.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg_ft.MODEL.ROI_HEADS.NUM_CLASSES = 1 # balloon 1클래스
os.makedirs(cfg_ft.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg_ft)
trainer.resume_or_load(resume=False)
trainer.train()
# ===============================
# 6. P3-3 AP/AR 측정 (fine-tune 전/후 비교)
# ===============================
# 6-1. Fine-tuning 이전 (COCO pretrained 상태)
cfg_pre = get_cfg()
cfg_pre.merge_from_file(model_zoo.get_config_file(model_name))
cfg_pre.MODEL.DEVICE = device
cfg_pre.DATASETS.TEST = ("balloon_val",)
cfg_pre.DATALOADER.NUM_WORKERS = 2
cfg_pre.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name)
cfg_pre.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7
pre_predictor = DefaultPredictor(cfg_pre)
evaluator_pre = COCOEvaluator("balloon_val", cfg_pre, False, output_dir="./outputs_p3/eval_pre/")
val_loader_pre = build_detection_test_loader(cfg_pre, "balloon_val")
metrics_pre = inference_on_dataset(pre_predictor.model, val_loader_pre, evaluator_pre)
print("[P3-3] Pretrained model metrics on balloon_val:")
print(metrics_pre)
# 6-2. Fine-tuning 이후 (balloon에 맞게 학습된 모델)
cfg_ft.MODEL.WEIGHTS = os.path.join(cfg_ft.OUTPUT_DIR, "model_final.pth")
cfg_ft.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7
ft_predictor = DefaultPredictor(cfg_ft)
evaluator_ft = COCOEvaluator("balloon_val", cfg_ft, False, output_dir="./outputs_p3/eval_ft/")
val_loader_ft = build_detection_test_loader(cfg_ft, "balloon_val")
metrics_ft = inference_on_dataset(ft_predictor.model, val_loader_ft, evaluator_ft)
print("[P3-3] Fine-tuned model metrics on balloon_val:")
print(metrics_ft)
# ===============================
# 7. P3-2: Fine-tuned 모델로 balloon/val 시각화
# ===============================
os.makedirs("./outputs_p3/finetuned_vis", exist_ok=True)
val_dicts = get_balloon_dicts("balloon/val")
for d in random.sample(val_dicts, min(10, len(val_dicts))):
im = cv2.imread(d["file_name"])
outputs = ft_predictor(im)
v = Visualizer(im[:, :, ::-1], balloon_metadata, scale=0.5)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
filename = os.path.basename(d["file_name"])
cv2.imwrite(f'./outputs_p3/finetuned_vis/{filename}', out.get_image()[:, :, ::-1])
print("[P3-2] Fine-tuned model visualizations saved to ./outputs_p3/finetuned_vis")
# ===============================
# 8. P3-4: 예시 이미지에 fine-tuned 모델 재적용
# ===============================
ft_out_path = "./outputs_p3/finetuned_pred.jpg"
ft_outputs = ft_predictor(img)
v = Visualizer(img[:, :, ::-1], balloon_metadata, scale=1.2)
ft_draw = v.draw_instance_predictions(ft_outputs["instances"].to("cpu"))
cv2.imwrite(ft_out_path, ft_draw.get_image()[:, :, ::-1])
print(f"[P3-4] Fine-tuned inference saved to: {ft_out_path}") Preparing metadata (setup.py) ... done
torch: 2.8 ; cuda: cu126
Using device: cuda
[11/19 22:35:57 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl ...
[P3-1] Pretrained inference saved to: ./outputs_p3/pretrained_pred.jpg
[P3-1] Pretrained model applied to some balloon/train images.
[11/19 22:36:04 d2.engine.defaults]: Model:
GeneralizedRCNN(
(backbone): FPN(
(fpn_lateral2): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral3): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral4): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fpn_lateral5): Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
(fpn_output5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(top_block): LastLevelMaxPool()
(bottom_up): ResNet(
(stem): BasicStem(
(conv1): Conv2d(
3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
)
(res2): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv1): Conv2d(
64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv2): Conv2d(
64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=64, eps=1e-05)
)
(conv3): Conv2d(
64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
)
)
(res3): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv1): Conv2d(
256, 128, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv2): Conv2d(
128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=128, eps=1e-05)
)
(conv3): Conv2d(
128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
)
)
(res4): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
(conv1): Conv2d(
512, 256, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(3): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(4): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
(5): BottleneckBlock(
(conv1): Conv2d(
1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=256, eps=1e-05)
)
(conv3): Conv2d(
256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=1024, eps=1e-05)
)
)
)
(res5): Sequential(
(0): BottleneckBlock(
(shortcut): Conv2d(
1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
(conv1): Conv2d(
1024, 512, kernel_size=(1, 1), stride=(2, 2), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(1): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
(2): BottleneckBlock(
(conv1): Conv2d(
2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv2): Conv2d(
512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=512, eps=1e-05)
)
(conv3): Conv2d(
512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False
(norm): FrozenBatchNorm2d(num_features=2048, eps=1e-05)
)
)
)
)
)
(proposal_generator): RPN(
(rpn_head): StandardRPNHead(
(conv): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(objectness_logits): Conv2d(256, 3, kernel_size=(1, 1), stride=(1, 1))
(anchor_deltas): Conv2d(256, 12, kernel_size=(1, 1), stride=(1, 1))
)
(anchor_generator): DefaultAnchorGenerator(
(cell_anchors): BufferList()
)
)
(roi_heads): StandardROIHeads(
(box_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(7, 7), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(box_head): FastRCNNConvFCHead(
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc1): Linear(in_features=12544, out_features=1024, bias=True)
(fc_relu1): ReLU()
(fc2): Linear(in_features=1024, out_features=1024, bias=True)
(fc_relu2): ReLU()
)
(box_predictor): FastRCNNOutputLayers(
(cls_score): Linear(in_features=1024, out_features=2, bias=True)
(bbox_pred): Linear(in_features=1024, out_features=4, bias=True)
)
(mask_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(14, 14), spatial_scale=0.25, sampling_ratio=0, aligned=True)
(1): ROIAlign(output_size=(14, 14), spatial_scale=0.125, sampling_ratio=0, aligned=True)
(2): ROIAlign(output_size=(14, 14), spatial_scale=0.0625, sampling_ratio=0, aligned=True)
(3): ROIAlign(output_size=(14, 14), spatial_scale=0.03125, sampling_ratio=0, aligned=True)
)
)
(mask_head): MaskRCNNConvUpsampleHead(
(mask_fcn1): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn2): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn3): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(mask_fcn4): Conv2d(
256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)
(activation): ReLU()
)
(deconv): ConvTranspose2d(256, 256, kernel_size=(2, 2), stride=(2, 2))
(deconv_relu): ReLU()
(predictor): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
)
)
)
[11/19 22:36:05 d2.data.build]: Removed 0 images with no usable annotations. 61 images left.
[11/19 22:36:05 d2.data.build]: Distribution of instances among all 1 categories:
| category | #instances |
|:----------:|:-------------|
| balloon | 255 |
| | |
[11/19 22:36:05 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in training: [ResizeShortestEdge(short_edge_length=(640, 672, 704, 736, 768, 800), max_size=1333, sample_style='choice'), RandomFlip()]
[11/19 22:36:05 d2.data.build]: Using training sampler TrainingSampler
[11/19 22:36:05 d2.data.common]: Serializing the dataset using: <class 'detectron2.data.common._TorchSerializedList'>
[11/19 22:36:05 d2.data.common]: Serializing 61 elements to byte tensors and concatenating them all ...
[11/19 22:36:05 d2.data.common]: Serialized dataset takes 0.17 MiB
[11/19 22:36:05 d2.data.build]: Making batched data loader with batch_size=2
[11/19 22:36:05 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl ...
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.box_predictor.cls_score.weight' to the model due to incompatible shapes: (81, 1024) in the checkpoint but (2, 1024) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.box_predictor.cls_score.bias' to the model due to incompatible shapes: (81,) in the checkpoint but (2,) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.box_predictor.bbox_pred.weight' to the model due to incompatible shapes: (320, 1024) in the checkpoint but (4, 1024) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.box_predictor.bbox_pred.bias' to the model due to incompatible shapes: (320,) in the checkpoint but (4,) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.mask_head.predictor.weight' to the model due to incompatible shapes: (80, 256, 1, 1) in the checkpoint but (1, 256, 1, 1) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Skip loading parameter 'roi_heads.mask_head.predictor.bias' to the model due to incompatible shapes: (80,) in the checkpoint but (1,) in the model! You might want to double check if this is expected.
WARNING:fvcore.common.checkpoint:Some model parameters or buffers are not found in the checkpoint:
roi_heads.box_predictor.bbox_pred.{bias, weight}
roi_heads.box_predictor.cls_score.{bias, weight}
roi_heads.mask_head.predictor.{bias, weight}
[11/19 22:36:05 d2.engine.train_loop]: Starting training from iteration 0
[11/19 22:36:17 d2.utils.events]: eta: 0:04:23 iter: 19 total_loss: 2.125 loss_cls: 0.6886 loss_box_reg: 0.6266 loss_mask: 0.686 loss_rpn_cls: 0.03407 loss_rpn_loc: 0.0111 time: 0.4478 last_time: 0.3928 data_time: 0.0248 last_data_time: 0.0075 lr: 8.1588e-06 max_mem: 2640M
[11/19 22:36:32 d2.utils.events]: eta: 0:04:21 iter: 39 total_loss: 1.879 loss_cls: 0.6236 loss_box_reg: 0.5417 loss_mask: 0.6403 loss_rpn_cls: 0.05174 loss_rpn_loc: 0.00641 time: 0.4592 last_time: 0.4727 data_time: 0.0060 last_data_time: 0.0070 lr: 1.6484e-05 max_mem: 2642M
[11/19 22:36:41 d2.utils.events]: eta: 0:04:10 iter: 59 total_loss: 1.74 loss_cls: 0.5314 loss_box_reg: 0.642 loss_mask: 0.571 loss_rpn_cls: 0.02232 loss_rpn_loc: 0.009098 time: 0.4595 last_time: 0.3531 data_time: 0.0071 last_data_time: 0.0088 lr: 2.4809e-05 max_mem: 2761M
[11/19 22:36:51 d2.utils.events]: eta: 0:04:02 iter: 79 total_loss: 1.644 loss_cls: 0.4187 loss_box_reg: 0.6741 loss_mask: 0.4438 loss_rpn_cls: 0.02835 loss_rpn_loc: 0.004551 time: 0.4613 last_time: 0.5015 data_time: 0.0089 last_data_time: 0.0124 lr: 3.3134e-05 max_mem: 2854M
[11/19 22:37:00 d2.utils.events]: eta: 0:03:56 iter: 99 total_loss: 1.534 loss_cls: 0.3844 loss_box_reg: 0.6932 loss_mask: 0.4172 loss_rpn_cls: 0.02204 loss_rpn_loc: 0.01052 time: 0.4638 last_time: 0.3646 data_time: 0.0064 last_data_time: 0.0081 lr: 4.1459e-05 max_mem: 2854M
[11/19 22:37:09 d2.utils.events]: eta: 0:03:46 iter: 119 total_loss: 1.244 loss_cls: 0.3162 loss_box_reg: 0.5993 loss_mask: 0.3367 loss_rpn_cls: 0.01998 loss_rpn_loc: 0.007439 time: 0.4628 last_time: 0.5293 data_time: 0.0104 last_data_time: 0.0084 lr: 4.9784e-05 max_mem: 2854M
[11/19 22:37:18 d2.utils.events]: eta: 0:03:34 iter: 139 total_loss: 1.26 loss_cls: 0.274 loss_box_reg: 0.6239 loss_mask: 0.2795 loss_rpn_cls: 0.01562 loss_rpn_loc: 0.003305 time: 0.4601 last_time: 0.3831 data_time: 0.0075 last_data_time: 0.0159 lr: 5.8109e-05 max_mem: 2854M
[11/19 22:37:27 d2.utils.events]: eta: 0:03:24 iter: 159 total_loss: 1.18 loss_cls: 0.2508 loss_box_reg: 0.6813 loss_mask: 0.2334 loss_rpn_cls: 0.01296 loss_rpn_loc: 0.007815 time: 0.4593 last_time: 0.3860 data_time: 0.0089 last_data_time: 0.0110 lr: 6.6434e-05 max_mem: 2854M
[11/19 22:37:37 d2.utils.events]: eta: 0:03:14 iter: 179 total_loss: 1.143 loss_cls: 0.2144 loss_box_reg: 0.6423 loss_mask: 0.2235 loss_rpn_cls: 0.03217 loss_rpn_loc: 0.008347 time: 0.4592 last_time: 0.4639 data_time: 0.0104 last_data_time: 0.0069 lr: 7.4759e-05 max_mem: 2854M
[11/19 22:37:46 d2.utils.events]: eta: 0:03:05 iter: 199 total_loss: 0.8878 loss_cls: 0.1658 loss_box_reg: 0.547 loss_mask: 0.1796 loss_rpn_cls: 0.01217 loss_rpn_loc: 0.007549 time: 0.4615 last_time: 0.4721 data_time: 0.0102 last_data_time: 0.0049 lr: 8.3084e-05 max_mem: 2854M
[11/19 22:37:56 d2.utils.events]: eta: 0:02:57 iter: 219 total_loss: 0.8898 loss_cls: 0.1748 loss_box_reg: 0.5322 loss_mask: 0.1379 loss_rpn_cls: 0.0177 loss_rpn_loc: 0.006383 time: 0.4622 last_time: 0.3566 data_time: 0.0072 last_data_time: 0.0010 lr: 9.1409e-05 max_mem: 2854M
[11/19 22:38:05 d2.utils.events]: eta: 0:02:48 iter: 239 total_loss: 0.7465 loss_cls: 0.1309 loss_box_reg: 0.4611 loss_mask: 0.1482 loss_rpn_cls: 0.006038 loss_rpn_loc: 0.007893 time: 0.4631 last_time: 0.4256 data_time: 0.0079 last_data_time: 0.0120 lr: 9.9734e-05 max_mem: 2856M
[11/19 22:38:14 d2.utils.events]: eta: 0:02:38 iter: 259 total_loss: 0.6634 loss_cls: 0.1191 loss_box_reg: 0.3318 loss_mask: 0.1427 loss_rpn_cls: 0.02504 loss_rpn_loc: 0.01367 time: 0.4623 last_time: 0.3950 data_time: 0.0073 last_data_time: 0.0057 lr: 0.00010806 max_mem: 2856M
[11/19 22:38:24 d2.utils.events]: eta: 0:02:29 iter: 279 total_loss: 0.5719 loss_cls: 0.1012 loss_box_reg: 0.2643 loss_mask: 0.1031 loss_rpn_cls: 0.01055 loss_rpn_loc: 0.008021 time: 0.4628 last_time: 0.4381 data_time: 0.0080 last_data_time: 0.0070 lr: 0.00011638 max_mem: 2856M
[11/19 22:38:33 d2.utils.events]: eta: 0:02:19 iter: 299 total_loss: 0.4108 loss_cls: 0.07032 loss_box_reg: 0.208 loss_mask: 0.09947 loss_rpn_cls: 0.01407 loss_rpn_loc: 0.006495 time: 0.4622 last_time: 0.5418 data_time: 0.0062 last_data_time: 0.0061 lr: 0.00012471 max_mem: 2856M
[11/19 22:38:42 d2.utils.events]: eta: 0:02:09 iter: 319 total_loss: 0.4215 loss_cls: 0.08639 loss_box_reg: 0.2221 loss_mask: 0.08764 loss_rpn_cls: 0.0125 loss_rpn_loc: 0.009378 time: 0.4621 last_time: 0.4219 data_time: 0.0075 last_data_time: 0.0064 lr: 0.00013303 max_mem: 2856M
[11/19 22:38:51 d2.utils.events]: eta: 0:02:00 iter: 339 total_loss: 0.3427 loss_cls: 0.0684 loss_box_reg: 0.1834 loss_mask: 0.07326 loss_rpn_cls: 0.01632 loss_rpn_loc: 0.006465 time: 0.4626 last_time: 0.4848 data_time: 0.0064 last_data_time: 0.0030 lr: 0.00014136 max_mem: 2856M
[11/19 22:39:01 d2.utils.events]: eta: 0:01:51 iter: 359 total_loss: 0.3487 loss_cls: 0.06907 loss_box_reg: 0.1775 loss_mask: 0.08248 loss_rpn_cls: 0.006231 loss_rpn_loc: 0.007402 time: 0.4634 last_time: 0.4702 data_time: 0.0071 last_data_time: 0.0056 lr: 0.00014968 max_mem: 2856M
[11/19 22:39:10 d2.utils.events]: eta: 0:01:42 iter: 379 total_loss: 0.3201 loss_cls: 0.06407 loss_box_reg: 0.1645 loss_mask: 0.08368 loss_rpn_cls: 0.01168 loss_rpn_loc: 0.005574 time: 0.4633 last_time: 0.3921 data_time: 0.0070 last_data_time: 0.0054 lr: 0.00015801 max_mem: 2856M
[11/19 22:39:19 d2.utils.events]: eta: 0:01:33 iter: 399 total_loss: 0.3537 loss_cls: 0.07944 loss_box_reg: 0.1591 loss_mask: 0.08075 loss_rpn_cls: 0.005371 loss_rpn_loc: 0.006123 time: 0.4628 last_time: 0.5090 data_time: 0.0080 last_data_time: 0.0100 lr: 0.00016633 max_mem: 2856M
[11/19 22:39:29 d2.utils.events]: eta: 0:01:23 iter: 419 total_loss: 0.2875 loss_cls: 0.06579 loss_box_reg: 0.1264 loss_mask: 0.06758 loss_rpn_cls: 0.009418 loss_rpn_loc: 0.004061 time: 0.4630 last_time: 0.5202 data_time: 0.0087 last_data_time: 0.0050 lr: 0.00017466 max_mem: 2856M
[11/19 22:39:38 d2.utils.events]: eta: 0:01:14 iter: 439 total_loss: 0.3398 loss_cls: 0.07117 loss_box_reg: 0.1437 loss_mask: 0.07306 loss_rpn_cls: 0.01138 loss_rpn_loc: 0.007898 time: 0.4631 last_time: 0.5265 data_time: 0.0072 last_data_time: 0.0112 lr: 0.00018298 max_mem: 2856M
[11/19 22:39:47 d2.utils.events]: eta: 0:01:05 iter: 459 total_loss: 0.318 loss_cls: 0.05196 loss_box_reg: 0.1325 loss_mask: 0.06987 loss_rpn_cls: 0.004073 loss_rpn_loc: 0.005413 time: 0.4627 last_time: 0.4723 data_time: 0.0069 last_data_time: 0.0051 lr: 0.00019131 max_mem: 2856M
[11/19 22:39:56 d2.utils.events]: eta: 0:00:55 iter: 479 total_loss: 0.3109 loss_cls: 0.06609 loss_box_reg: 0.1356 loss_mask: 0.0743 loss_rpn_cls: 0.00909 loss_rpn_loc: 0.00815 time: 0.4625 last_time: 0.4424 data_time: 0.0078 last_data_time: 0.0054 lr: 0.00019963 max_mem: 2856M
[11/19 22:40:05 d2.utils.events]: eta: 0:00:46 iter: 499 total_loss: 0.2729 loss_cls: 0.0533 loss_box_reg: 0.1307 loss_mask: 0.07274 loss_rpn_cls: 0.00567 loss_rpn_loc: 0.004707 time: 0.4627 last_time: 0.4480 data_time: 0.0099 last_data_time: 0.0054 lr: 0.00020796 max_mem: 2856M
[11/19 22:40:15 d2.utils.events]: eta: 0:00:37 iter: 519 total_loss: 0.2655 loss_cls: 0.05891 loss_box_reg: 0.1356 loss_mask: 0.06022 loss_rpn_cls: 0.01057 loss_rpn_loc: 0.006509 time: 0.4626 last_time: 0.5029 data_time: 0.0074 last_data_time: 0.0069 lr: 0.00021628 max_mem: 2856M
[11/19 22:40:23 d2.utils.events]: eta: 0:00:27 iter: 539 total_loss: 0.233 loss_cls: 0.04788 loss_box_reg: 0.1153 loss_mask: 0.05859 loss_rpn_cls: 0.004958 loss_rpn_loc: 0.004156 time: 0.4616 last_time: 0.4195 data_time: 0.0059 last_data_time: 0.0048 lr: 0.00022461 max_mem: 2856M
[11/19 22:40:33 d2.utils.events]: eta: 0:00:18 iter: 559 total_loss: 0.22 loss_cls: 0.05432 loss_box_reg: 0.1011 loss_mask: 0.06405 loss_rpn_cls: 0.009948 loss_rpn_loc: 0.006521 time: 0.4619 last_time: 0.4204 data_time: 0.0079 last_data_time: 0.0070 lr: 0.00023293 max_mem: 2856M
[11/19 22:40:43 d2.utils.events]: eta: 0:00:09 iter: 579 total_loss: 0.2054 loss_cls: 0.03729 loss_box_reg: 0.1024 loss_mask: 0.05099 loss_rpn_cls: 0.005095 loss_rpn_loc: 0.005016 time: 0.4626 last_time: 0.4739 data_time: 0.0079 last_data_time: 0.0115 lr: 0.00024126 max_mem: 2856M
[11/19 22:40:57 d2.utils.events]: eta: 0:00:00 iter: 599 total_loss: 0.3036 loss_cls: 0.05905 loss_box_reg: 0.1445 loss_mask: 0.07434 loss_rpn_cls: 0.005291 loss_rpn_loc: 0.007706 time: 0.4619 last_time: 0.3862 data_time: 0.0072 last_data_time: 0.0139 lr: 0.00024958 max_mem: 2856M
[11/19 22:40:57 d2.engine.hooks]: Overall training speed: 598 iterations in 0:04:36 (0.4619 s / it)
[11/19 22:40:57 d2.engine.hooks]: Total training time: 0:04:48 (0:00:12 on hooks)
[11/19 22:40:57 d2.data.build]: Distribution of instances among all 1 categories:
| category | #instances |
|:----------:|:-------------|
| balloon | 50 |
| | |
[11/19 22:40:57 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in inference: [ResizeShortestEdge(short_edge_length=(800, 800), max_size=1333, sample_style='choice')]
[11/19 22:40:57 d2.data.common]: Serializing the dataset using: <class 'detectron2.data.common._TorchSerializedList'>
[11/19 22:40:57 d2.data.common]: Serializing 13 elements to byte tensors and concatenating them all ...
[11/19 22:40:57 d2.data.common]: Serialized dataset takes 0.04 MiB
WARNING [11/19 22:40:57 d2.engine.defaults]: No evaluator found. Use `DefaultTrainer.test(evaluators=)`, or implement its `build_evaluator` method.
[11/19 22:40:58 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from https://dl.fbaipublicfiles.com/detectron2/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl ...
WARNING [11/19 22:40:58 d2.evaluation.coco_evaluation]: COCO Evaluator instantiated using config, this is deprecated behavior. Please pass in explicit arguments instead.
[11/19 22:40:58 d2.evaluation.coco_evaluation]: Trying to convert 'balloon_val' to COCO format ...
[11/19 22:40:58 d2.data.datasets.coco]: Converting annotations of dataset 'balloon_val' to COCO format ...)
[11/19 22:40:58 d2.data.datasets.coco]: Converting dataset dicts into COCO format
[11/19 22:40:58 d2.data.datasets.coco]: Conversion finished, #images: 13, #annotations: 50
[11/19 22:40:58 d2.data.datasets.coco]: Caching COCO format annotations at './outputs_p3/eval_pre/balloon_val_coco_format.json' ...
[11/19 22:40:59 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in inference: [ResizeShortestEdge(short_edge_length=(800, 800), max_size=1333, sample_style='choice')]
[11/19 22:40:59 d2.data.common]: Serializing the dataset using: <class 'detectron2.data.common._TorchSerializedList'>
[11/19 22:40:59 d2.data.common]: Serializing 13 elements to byte tensors and concatenating them all ...
[11/19 22:40:59 d2.data.common]: Serialized dataset takes 0.04 MiB
[11/19 22:40:59 d2.evaluation.evaluator]: Start inference on 13 batches
[11/19 22:41:01 d2.evaluation.evaluator]: Inference done 11/13. Dataloading: 0.0016 s/iter. Inference: 0.1226 s/iter. Eval: 0.0195 s/iter. Total: 0.1438 s/iter. ETA=0:00:00
[11/19 22:41:01 d2.evaluation.evaluator]: Total inference time: 0:00:01.193024 (0.149128 s / iter per device, on 1 devices)
[11/19 22:41:01 d2.evaluation.evaluator]: Total inference pure compute time: 0:00:00 (0.118545 s / iter per device, on 1 devices)
[11/19 22:41:01 d2.evaluation.coco_evaluation]: Preparing results for COCO format ...
[11/19 22:41:01 d2.evaluation.coco_evaluation]: Saving results to ./outputs_p3/eval_pre/coco_instances_results.json
[11/19 22:41:01 d2.evaluation.coco_evaluation]: Evaluating predictions with unofficial COCO API...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
[11/19 22:41:01 d2.evaluation.fast_eval_api]: Evaluate annotation type *bbox*
[11/19 22:41:01 d2.evaluation.fast_eval_api]: COCOeval_opt.evaluate() finished in 0.00 seconds.
[11/19 22:41:01 d2.evaluation.fast_eval_api]: Accumulating evaluation results...
[11/19 22:41:01 d2.evaluation.fast_eval_api]: COCOeval_opt.accumulate() finished in 0.01 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
[11/19 22:41:01 d2.evaluation.coco_evaluation]: Evaluation results for bbox:
| AP | AP50 | AP75 | APs | APm | APl |
|:-----:|:------:|:------:|:-----:|:-----:|:-----:|
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
[11/19 22:41:01 d2.evaluation.fast_eval_api]: Evaluate annotation type *segm*
[11/19 22:41:01 d2.evaluation.fast_eval_api]: COCOeval_opt.evaluate() finished in 0.01 seconds.
[11/19 22:41:01 d2.evaluation.fast_eval_api]: Accumulating evaluation results...
[11/19 22:41:01 d2.evaluation.fast_eval_api]: COCOeval_opt.accumulate() finished in 0.00 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.000
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.000
[11/19 22:41:01 d2.evaluation.coco_evaluation]: Evaluation results for segm:
| AP | AP50 | AP75 | APs | APm | APl |
|:-----:|:------:|:------:|:-----:|:-----:|:-----:|
| 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
[P3-3] Pretrained model metrics on balloon_val:
OrderedDict({'bbox': {'AP': 0.0, 'AP50': 0.0, 'AP75': 0.0, 'APs': 0.0, 'APm': 0.0, 'APl': 0.0}, 'segm': {'AP': 0.0, 'AP50': 0.0, 'AP75': 0.0, 'APs': 0.0, 'APm': 0.0, 'APl': 0.0}})
[11/19 22:41:02 d2.checkpoint.detection_checkpoint]: [DetectionCheckpointer] Loading from ./output/model_final.pth ...
WARNING [11/19 22:41:03 d2.evaluation.coco_evaluation]: COCO Evaluator instantiated using config, this is deprecated behavior. Please pass in explicit arguments instead.
[11/19 22:41:03 d2.data.dataset_mapper]: [DatasetMapper] Augmentations used in inference: [ResizeShortestEdge(short_edge_length=(800, 800), max_size=1333, sample_style='choice')]
[11/19 22:41:03 d2.data.common]: Serializing the dataset using: <class 'detectron2.data.common._TorchSerializedList'>
[11/19 22:41:03 d2.data.common]: Serializing 13 elements to byte tensors and concatenating them all ...
[11/19 22:41:03 d2.data.common]: Serialized dataset takes 0.04 MiB
[11/19 22:41:03 d2.evaluation.evaluator]: Start inference on 13 batches
[11/19 22:41:05 d2.evaluation.evaluator]: Total inference time: 0:00:00.982844 (0.122856 s / iter per device, on 1 devices)
[11/19 22:41:05 d2.evaluation.evaluator]: Total inference pure compute time: 0:00:00 (0.109083 s / iter per device, on 1 devices)
[11/19 22:41:05 d2.evaluation.coco_evaluation]: Preparing results for COCO format ...
[11/19 22:41:05 d2.evaluation.coco_evaluation]: Saving results to ./outputs_p3/eval_ft/coco_instances_results.json
[11/19 22:41:05 d2.evaluation.coco_evaluation]: Evaluating predictions with unofficial COCO API...
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
[11/19 22:41:05 d2.evaluation.fast_eval_api]: Evaluate annotation type *bbox*
[11/19 22:41:05 d2.evaluation.fast_eval_api]: COCOeval_opt.evaluate() finished in 0.00 seconds.
[11/19 22:41:05 d2.evaluation.fast_eval_api]: Accumulating evaluation results...
[11/19 22:41:05 d2.evaluation.fast_eval_api]: COCOeval_opt.accumulate() finished in 0.00 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.723
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.857
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.807
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.303
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.512
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.880
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.236
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.744
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.744
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.300
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.547
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.900
[11/19 22:41:05 d2.evaluation.coco_evaluation]: Evaluation results for bbox:
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:------:|:------:|:------:|:------:|:------:|
| 72.345 | 85.733 | 80.707 | 30.297 | 51.193 | 87.981 |
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
[11/19 22:41:05 d2.evaluation.fast_eval_api]: Evaluate annotation type *segm*
[11/19 22:41:05 d2.evaluation.fast_eval_api]: COCOeval_opt.evaluate() finished in 0.01 seconds.
[11/19 22:41:05 d2.evaluation.fast_eval_api]: Accumulating evaluation results...
[11/19 22:41:05 d2.evaluation.fast_eval_api]: COCOeval_opt.accumulate() finished in 0.00 seconds.
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.775
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.835
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.835
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.236
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.501
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.968
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.256
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.786
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.786
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.233
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.547
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.977
[11/19 22:41:05 d2.evaluation.coco_evaluation]: Evaluation results for segm:
| AP | AP50 | AP75 | APs | APm | APl |
|:------:|:------:|:------:|:------:|:------:|:------:|
| 77.506 | 83.504 | 83.504 | 23.564 | 50.077 | 96.813 |
[P3-3] Fine-tuned model metrics on balloon_val:
OrderedDict({'bbox': {'AP': 72.34481209679068, 'AP50': 85.73285748511225, 'AP75': 80.7072913017707, 'APs': 30.297029702970296, 'APm': 51.19346000534119, 'APl': 87.9805866223441}, 'segm': {'AP': 77.50560590695736, 'AP50': 83.50441884061152, 'AP75': 83.50441884061152, 'APs': 23.564356435643564, 'APm': 50.07715057220008, 'APl': 96.81317875377282}})
[P3-2] Fine-tuned model visualizations saved to ./outputs_p3/finetuned_vis
[P3-4] Fine-tuned inference saved to: ./outputs_p3/finetuned_pred.jpg









0. 전체 흐름 한 줄 요약
- 3-1: COCO로 학습된 Mask R-CNN 하나 골라서 → 예시 이미지에 적용 → 시각화 + “왜 이 모델 골랐는지” 설명
- 3-2: balloon train/val dataset 등록 → train으로 fine-tuning → val 이미지에 대한 결과 시각화
- 3-3:
- fine-tuning 전(pretrained COCO 모델) AP/AR
- fine-tuning 후(balloon에 맞게 학습된 모델) AP/AR
- 하이퍼파라미터를 바꾸면서 결과 비교
- 3-4:
- 3-1에서 썼던 예시 이미지에 대해 fine-tuning 후 모델로 다시 inference
- “왜 이런 결과가 나왔는지” + “어떻게 개선할 수 있을지” 분석 글 작성
1. 3-1: 사전학습 모델 선택 + 예시 이미지 시각화 + 선정 이유
1) 모델 선택
보통 과제에서 가장 무난한 선택은:
model_name = "COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"
선택 이유를 리포트에 이렇게 쓰면 좋아:
- ResNet-50 + FPN 백본이라 **성능(mAP)**과 **속도(inference time)**의 균형이 좋음
- Model Zoo에서 자주 baseline으로 쓰이는 구조라, 과제에서 비교/확장에 적합
- ResNet-101은 성능은 높지만 inference 속도가 느리고, R-50-FPN이 실제 서비스/실험용으로 많이 쓰임
예시 문장:
본 실험에서는 Detectron2 Model Zoo에서 제공하는 mask_rcnn_R_50_FPN_3x 사전학습 모델을 사용하였다. 해당 모델은 ResNet-50 백본과 FPN 구조를 사용하여 COCO val2017 기준으로 비교적 높은 mAP를 유지하면서도, ResNet-101 기반 모델에 비해 파라미터 수와 연산량이 적어 inference time 측면에서 효율적이다. 따라서 성능과 속도의 균형을 고려하여 본 모델을 선정하였다.
2) 예시 이미지 추론 / 시각화
기본 구조는 이미 가지고 있지:
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file(model_name))
cfg.MODEL.DEVICE = "cpu" # GPU 없으면 반드시 추가
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name)
predictor = DefaultPredictor(cfg)
img_path = "./img_for_P3.jpg" # wget으로 다운로드한 이미지
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
assert img is not None, "예시 이미지를 먼저 다운로드하세요."
outputs = predictor(img)
os.makedirs("./outputs_p3", exist_ok=True)
v = Visualizer(img[:, :, ::-1], MetadataCatalog.get("__unused__"), scale=1.2)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
cv2.imwrite("./outputs_p3/pretrained_pred.jpg", out.get_image()[:, :, ::-1])리포트에는:
- “사전학습된 COCO 모델이 사람, 자동차, 기타 물체에 대해 적절히 mask를 생성하는지”
- “어떤 객체들은 잘 잡고, 어떤 것들은 누락/오탐이 있는지”
짧게 코멘트 써주면 좋아.
2. 3-2: 풍선 데이터셋 fine-tuning (train/val 확인 + 시각화)
1) Dataset 등록 및 시각화
너 코드에 이미 있는:
for d in ["train", "val"]:
if "balloon_" + d in DatasetCatalog.list():
DatasetCatalog.remove("balloon_" + d)
DatasetCatalog.register("balloon_" + d, lambda d=d: get_balloon_dicts("balloon/" + d))
MetadataCatalog.get("balloon_" + d).set(thing_classes=["balloon"])
balloon_metadata = MetadataCatalog.get("balloon_train")
dataset_dicts = get_balloon_dicts("balloon/train")그리고 시각화:
os.makedirs("./outputs_p3/pretrained_balloon", exist_ok=True)
random.seed(1234)
for d in random.sample(dataset_dicts, 5): # 5장만 예시
im = cv2.imread(d["file_name"])
outputs = predictor(im) # 아직은 COCO pretrained 모델
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=0.5)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
filename = os.path.basename(d["file_name"])
cv2.imwrite(f'./outputs_p3/pretrained_balloon/{filename}', out.get_image()[:, :, ::-1])리포트 서술 포인트:
- 풍선 데이터셋은 “작고, 단일 클래스(balloon)”라는 특징
- train/val 예시 이미지를 통해 annotation이 정상적으로 잘 들어가 있는지 간단히 확인했다는 내용
2) Fine-tuning 코드 핵심
너가 이미 적어둔 구조:
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file(model_name))
cfg.MODEL.DEVICE = "cpu" # CPU 환경이면 추가
cfg.DATASETS.TRAIN = ("balloon_train",)
cfg.DATASETS.TEST = ("balloon_val",)
cfg.DATALOADER.NUM_WORKERS = 2
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name) # COCO pretrained
cfg.SOLVER.IMS_PER_BATCH = 2
cfg.SOLVER.BASE_LR = 0.00025
cfg.SOLVER.MAX_ITER = 600 # 과제에서는 300~1000 사이 실험 추천
cfg.SOLVER.STEPS = []
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 128
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 1 # balloon 클래스 1개
os.makedirs(cfg.OUTPUT_DIR, exist_ok=True)
trainer = DefaultTrainer(cfg)
trainer.resume_or_load(resume=False)
trainer.train()그리고 val 시각화:
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7
predictor = DefaultPredictor(cfg)
os.makedirs("./outputs_p3/finetuned_vis", exist_ok=True)
for d in random.sample(get_balloon_dicts("balloon/val"), 5):
im = cv2.imread(d["file_name"])
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1], balloon_metadata, scale=0.5)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
filename = os.path.basename(d["file_name"])
cv2.imwrite(f'./outputs_p3/finetuned_vis/{filename}', out.get_image()[:, :, ::-1])리포트에는:
- fine-tuning 후, COCO 사전학습 모델보다 풍선 경계가 얼마나 더 정확해졌는지
- 작은 풍선/겹쳐진 풍선에 대한 성능이 향상되었는지 여부
이런 걸 이미지 예시와 함께 짧게 설명해주면 좋아.
3. 3-3: 파인 튜닝 전후 AP/AR 계산 + 파라미터 실험
여기가 채점 포인트가 큰 부분이라 구조 + 서술이 중요해.

1) Pretrained vs Fine-tuned 평가 코드 패턴
(1) 파인튜닝 “이전” (COCO pretrained)
from detectron2.evaluation import COCOEvaluator, inference_on_dataset
from detectron2.data import build_detection_test_loader
cfg_pre = get_cfg()
cfg_pre.merge_from_file(model_zoo.get_config_file(model_name))
cfg_pre.MODEL.DEVICE = "cpu"
cfg_pre.DATASETS.TEST = ("balloon_val",)
cfg_pre.DATALOADER.NUM_WORKERS = 2
cfg_pre.MODEL.WEIGHTS = model_zoo.get_checkpoint_url(model_name)
cfg_pre.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.7
pre_predictor = DefaultPredictor(cfg_pre)
evaluator_pre = COCOEvaluator("balloon_val", cfg_pre, False, output_dir="./outputs_p3/eval_pre/")
val_loader_pre = build_detection_test_loader(cfg_pre, "balloon_val")
metrics_pre = inference_on_dataset(pre_predictor.model, val_loader_pre, evaluator_pre)
print("Pretrained model metrics:", metrics_pre)(2) 파인튜닝 “이후” (balloon에 맞게 학습된 모델)
cfg_ft = cfg.clone() # 앞에서 fine-tuning에 사용한 cfg
cfg_ft.MODEL.DEVICE = "cpu"
cfg_ft.DATASETS.TEST = ("balloon_val",)
evaluator_ft = COCOEvaluator("balloon_val", cfg_ft, False, output_dir="./outputs_p3/eval_ft/")
val_loader_ft = build_detection_test_loader(cfg_ft, "balloon_val")
metrics_ft = inference_on_dataset(predictor.model, val_loader_ft, evaluator_ft)
print("Fine-tuned model metrics:", metrics_ft)- bbox, segm 기준의 AP, AP50, AP75, AP_small, AP_medium, AP_large
- 그리고 AR(Average Recall)들도 들어있을 거야.
리포트에서는 중요한 것만 골라서 표로 정리:
| Pretrained (no FT) | 0.xx | 0.xx | 0.xx | COCO pretrained, no FT |
| Fine-tuned (iter=300) | 0.yy | 0.yy | 0.yy | lr=0.00025, iter=300 |
| Fine-tuned (iter=600) | 0.zz | 0.zz | 0.zz | lr=0.00025, iter=600 |
2) “여러 파라미터 변경”은 어떻게 할까?
추천 실험 축:
- MAX_ITER
- 300, 600, 900 정도
- iter가 늘어날수록 AP가 증가하다가, 어느 시점부터 과적합으로 떨어지거나 plateau
- BASE_LR
- 0.0001 vs 0.00025 vs 0.001
- 너무 크면 발산, 너무 작으면 수렴이 느리고 AP 낮음
- ROI_HEADS.BATCH_SIZE_PER_IMAGE
- 64 vs 128
- RoI 샘플 수 바꾸면서 성능/시간 비교
리포트에서는:
MAX_ITER를 300, 600, 900으로 변경하여 실험한 결과, 300에서 AP는 X.XXX, 600에서 Y.YYY로 증가하였으나, 900에서는 성능 향상이 크지 않거나 소폭 감소하였다. 이는 풍선 데이터셋의 크기가 작기 때문에, 반복 수를 과도하게 늘릴 경우 풍선 영역에 과적합(overfitting)이 발생한 것으로 해석할 수 있다.
이런 식으로 AP/AR 변화 + 이유를 써주면 된다.
4. 3-4: 예시 이미지에서 나타나는 문제 분석 + 개선 방향
마지막 파트는 코드보다 글이 더 중요해.
1) 할 일
- 3-1에서 사용한 img_for_P3.jpg를
- fine-tuned 모델(predictor)으로 다시 inference
ft_out_path = "./outputs_p3/finetuned_pred.jpg"
ft_outputs = predictor(img) # 위에서 이미 img = cv2.imread(img_for_P3.jpg)
v = Visualizer(img[:, :, ::-1], balloon_metadata, scale=1.2)
ft_draw = v.draw_instance_predictions(ft_outputs["instances"].to("cpu"))
cv2.imwrite(ft_out_path, ft_draw.get_image()[:, :, ::-1))2) 분석에서 자주 나오는 “문제 상황”
대부분 이런 현상이 나타날 수 있어:
- COCO 전체 객체를 인식하던 모델이 → 이제 풍선에만 과하게 반응
- 풍선이 아닌 둥근/빨간 객체도 balloon으로 잘못 segmentation (false positive)
- 원래 잘 잡던 사람/차량/배경 객체는 더 이상 검출하지 않음
- 이유: NUM_CLASSES = 1로 설정해서 COCO 멀티클래스 정보가 덮여씀
3) 리포트에 쓸 수 있는 예시 분석 문장
Fine-tuning 이후 3-1에서 사용한 COCO val 이미지에 대해 재추론을 수행한 결과, 풍선과 유사한 색상 또는 형태를 가진 영역에 대해서는 과도하게 balloon mask가 예측되는 반면, 원래 사전학습 모델이 잘 검출하던 사람, 차량 등의 일반 객체는 거의 검출되지 않았다. 이는 풍선 데이터셋이 단일 클래스에 대한 소규모 데이터로 구성되어 있고, fine-tuning 과정에서 ROI_HEADS.NUM_CLASSES를 1로 설정함으로써 COCO의 멀티 클래스 표현력이 상당 부분 상실되었기 때문으로 해석할 수 있다.
또한 MAX_ITER를 크게 설정한 경우, balloon 데이터셋에 대한 과적합이 발생하여 풍선과 유사한 둥근 객체(예: 표지판, 특정 장식물)에 대해 false positive가 증가하는 현상이 관찰되었다.
4) “어떻게 해결할 수 있을지” 제안
- 해결 아이디어 예시:
- 풍선뿐 아니라 다양한 객체가 포함된 추가 데이터로 multi-class fine-tuning 수행
- backbone을 동결(freeze)하고 ROI head만 미세 조정하여 과적합을 완화
- learning rate를 줄이거나, MAX_ITER를 조정해 과도한 업데이트 방지
- 강한 augmentation (scale jittering, color jitter, random crop)으로 데이터 다양성 증가
- SCORE_THRESH_TEST를 올려서 confidence가 낮은 false positive를 줄이기
리포트용 문장 예시:
이러한 문제를 완화하기 위한 방안으로는 (1) 풍선 외의 다양한 객체를 포함한 데이터로 multi-class fine-tuning을 수행하거나, (2) backbone을 동결하고 ROI head만 미세 조정하여 COCO 사전학습 표현을 최대한 보존하는 방법이 있다. 또한 (3) MAX_ITER와 BASE_LR을 조정하여 과도한 파라미터 업데이트를 방지하고, (4) 풍선 데이터셋에 대한 강한 데이터 증강을 적용함으로써 모델의 일반화 성능을 향상시킬 수 있을 것으로 판단된다.
마무리
지금까지 한 걸 정리하면:
- 코드 측면:
- 모델 선택 → 예시 이미지 inference
- balloon dataset 등록 → fine-tuning → val 시각화
- COCOEvaluator로 pretrained / fine-tuned 둘 다 AP/AR 측정
- 예시 이미지 재추론
- 리포트 측면:
- 왜 R50-FPN 3x를 선택했는지
- balloon dataset 특성 (소규모, single-class)
- 파라미터 변화에 따른 AP/AR 표 + 해석
- fine-tuning 이후 COCO 이미지에서 나타나는 문제와 개선 아이디어
이 네 축만 잘 채우면 P3 문제는 충분히 높은 점수 나올 구조야.
'개인 프로젝트 > 대학원 수업 정리' 카테고리의 다른 글
| [CV] 기말고사 정리 (0) | 2025.12.03 |
|---|---|
| [CV] Classification, Segmentation (0) | 2025.12.02 |
| [CV] 과제3_문제2 (0) | 2025.11.20 |
| [논문리뷰] CharGrid OCR 중요 원리 (0) | 2025.11.19 |
| [CV] 과제 3 최종코드 (0) | 2025.11.16 |


댓글